
RTX4070Ti作为2023年的第一张显卡,如期与我们见面,今天为您带来技嘉 RTX4070Ti GAMING OC 12G这张显卡的首次测试。

作为RTX40系列显卡的第一个Ti产品,它的出现实际上更像是一个意外。通过这次RTX4070Ti的参数,与之前公布的RTX408012G相比,发现CUDA的数量、核心频率、显存等数据都是一样的。
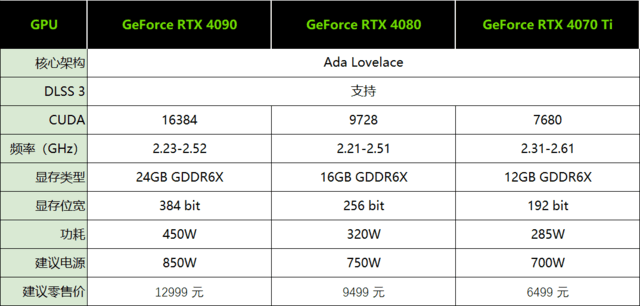
但有一点不同就是降价!RTX4080 12GB的价格最初是7199元,现在更名后的RTX4070Ti官方建议价格是6499元,直接下降了700元。
事实上,作为一款中高端型号的显卡,如果参考RTX30系列,6499元这个价格还是太贵了,毕竟当年的RTX3080作为次旗舰只有5499元。但在RTX4080售价9499元的背景下,似乎也相当便宜。接下来我们来看一下这款技嘉 RTX4070Ti GAMING OC12G显卡的性能表现。

技嘉 RTX4070Ti Gaming OC 12G电子竞技游戏设计智能学习计算机独立显卡支持4K。
[经销商]京东商城。
[产品价格]6999元。
技嘉 RTX4070Ti GAMING OC 12G概览。
RTX40系列显卡中技嘉 RTX4070Ti GAMING OC的变化也比较大,整体以黑色为主。但作为技嘉旗下的平价系列显卡,更加实用。


在配件方面,由于技嘉 RTX4070Ti GAMING OC采用了尾部和机箱的固定称重,因此没有传统的显卡支架,并且还附有一包螺丝用于固定。
此外,尽管RTX4070Ti的功耗有所下降,但RTX40系的所有员工都采用了16pin供电接口,因此还附有一条双8pin转接线。

作为一款中高端性能显卡,技嘉 RTX4070Ti GAMING OC的整体尺寸为336×140×58mm,而且是RTX40系列,尺寸相对较小。

在散热方面,技嘉 RTX4070Ti GAMING OC采用了三个直径为100毫米的9叶风扇,仍然是正逆转设计,配备了智能启停技术。7根复合铜热管用于内部散热,对RTX4070Ti来说已经足够了。

值得注意的是,技嘉 RTX4070Ti GAMING OC在风扇上采用了石墨烯纳米润滑剂,官方表示,它能使风扇使用寿命延长2.1倍,接近双滚珠轴承使用寿命,而且更加安静。

此次技嘉 RTX4070Ti GAMING OC的背板设计也相当简洁,整体为裸色金属,加上一些线条装饰,形成立体视觉效果。
然而,最令人震惊的是,从镂空部分目测到的PCB尺寸几乎只有整张卡的一半大小,其余部分都是散热系统。

HDMI2.1+DP1.4a*3的四接口设计仍然是视频输出界面。HDMI2.1可以支持4K120HzHDR和8K60HzHDR。

此次RTX4070Ti采用单16pin辅助供电,推荐750W及以上的电源。但是,从这个包装中附带的双8pin转接线也可以看出,以前的电源完全可以适应,但是NVIDIA这个统一的接口,所以只能在中间转接这个接口。
尽管功率没有那么大,但是有条件的话还是建议大家选择ATX3.0电源,它自带12VHPWR的16pin电源接口,最多可以支持600W电源。
值得注意的是,目前RTX30系列的12pin接口和电源转接器与RTX40系列显卡不兼容。
BIOS切换拨杆位于供电接口上方,BIOSOC即性能模式位于左侧,而SILENT安静模式位于右侧,玩家获得后默认为性能模式。
2技嘉智能管家(GCC)软件和灯光。
这次技嘉的控制软件再一次更新,与上一版相比,整体UI设计更加美观,操作方法也更加简洁。
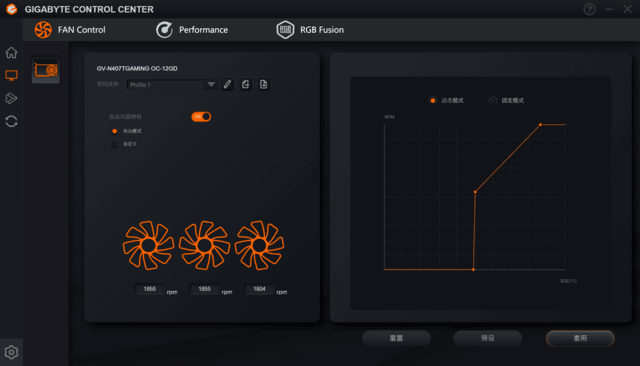
显卡的可调节部分在第二栏,包括风扇、超频和灯光调节。一些玩家可以选择默认的自动模式,或者根据自己的超频情况设置自定义模式,并支持当前配置文件的保存或导入。
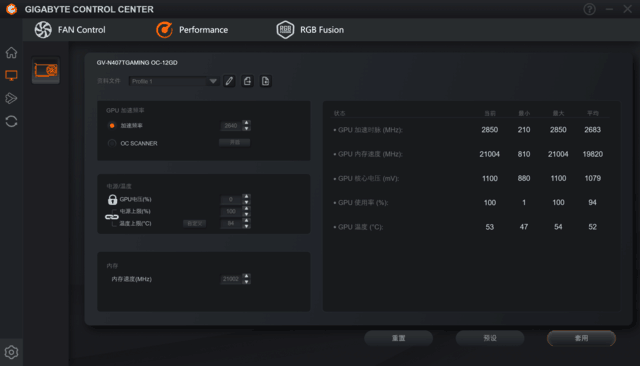
超频界面也比较简单,简化了很多操作。玩家主要调整加速频率,但如果要超频,也需要相应的压力和功耗。其实关于超频的技巧并不多,就是一点一点尝试,这也是超频的乐趣。界面最右边是显卡目前的参数。
RGB灯光调节界面非常贴心地为大家设置了一个较大的大雕刻logo,方便在取色时直接观看效果。

技嘉 RTX4070Ti GAMING OC的背光仍然在风扇内圈,但与上一代直接将灯珠安装在风扇上相比,风扇内圈发光的方式视觉效果更好,不会出现那么多视觉残影。
浅析了3NVIDIAGeForceRTX4070Ti架构。
GeForceRTX40系列显卡由全新的NVIDIAAdaLovelace架构构成,TSMC4NVIDIA定制技术,旗舰核心AD102达到760亿个可怕的晶体管,而RTX30系列显卡则达到280亿个。
NVIDIAAmpere与上一代NVIDIAAdaLovelace相比,在相同的功率下,NVIDIAAdaLovelace的性能提升量是90-TFLOPS的最大吞吐量。
GeForceRTX4070Ti的发布达到40-TFLOPS,而RTX4090最近的发布是83-TFLOPs。
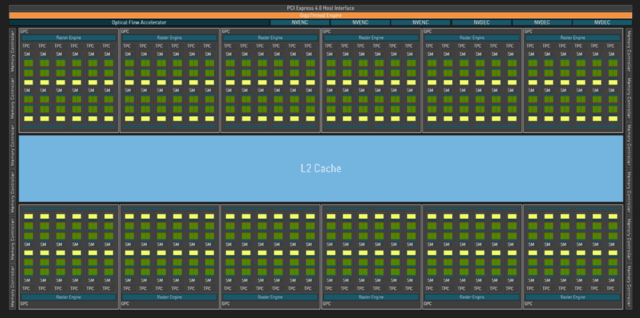
完整的AD102核心。

完整的AD104核心。
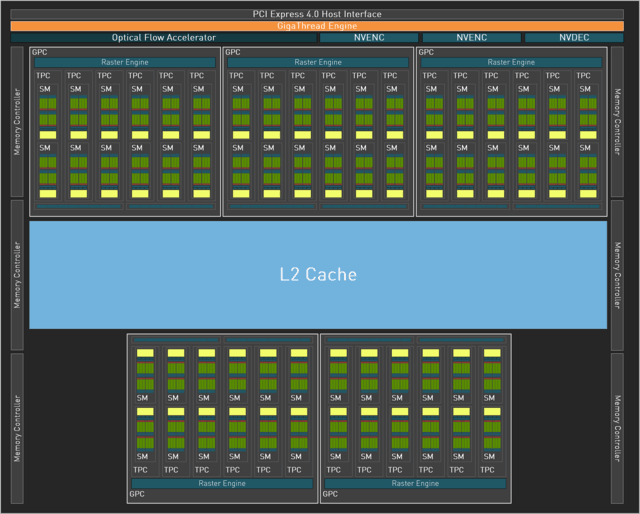
AD104用于RTX4070Ti。
GeForceRTX4070Ti这次使用了AD104芯片,标准的5组GPC,NVENC单元减少了3个。
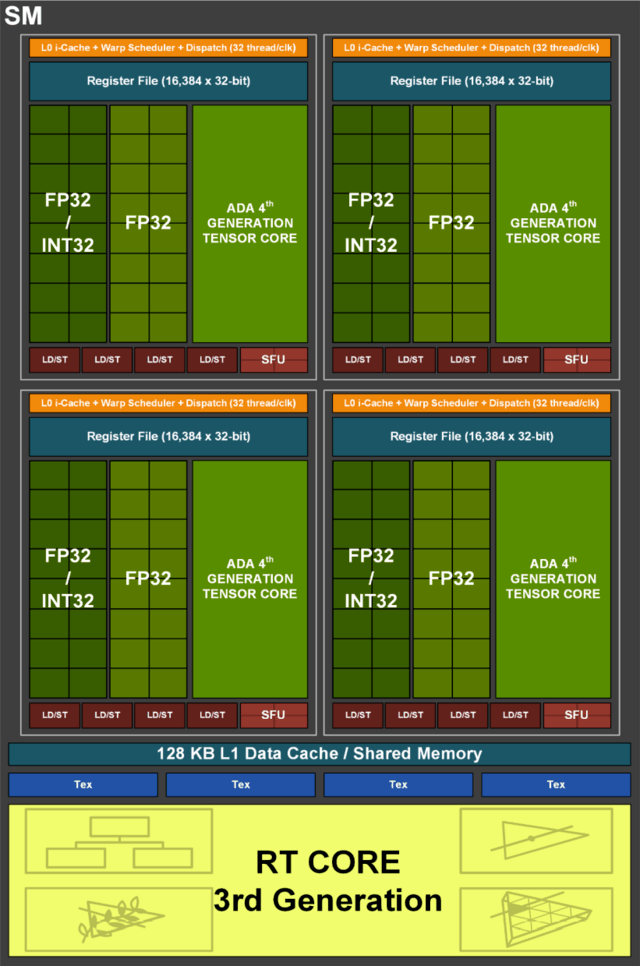
让我们详细看一下每一个SM单元,其中FP32CUDA核心与NVIDIAAmpere架构相同,FP32/INT32混合CUDA核心相同,L1级缓存相同等。当然,TensorCore在每个SM单元内部升级为第四代。

然而,最显著的变化是第三代光追核心,我们结合两代结构来看。BoxIntersectionEngine引擎,以及负责边界交叉测试的TriangleIntersectionEngine引擎,都是第二代光追核心。

而且在第三代光追核心中,还增加了两个新的引擎OpacityMicro-MapEngines(OMM)和DisplacedMicro-MeshEngines(DMM),这两个新的硬件单元可以大大提高光追性能(详细介绍了具体原理)。
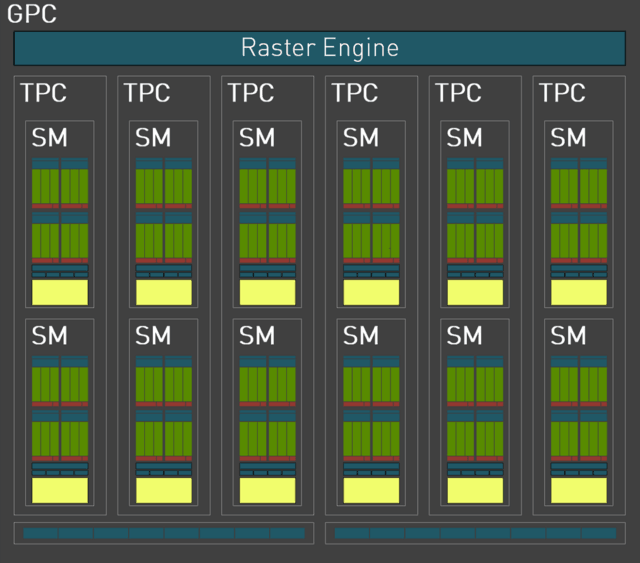
到目前为止,每两个SM单元形成一个TPC单元,每六个TPC单元形成一个完整的GPC顶层单元(在一些核心中,将有5个TPC单元形成一个GPC单元)。
而且每一个GPC单元都配备了独立的光栅引擎,两组ROP分区(每组包含8个ROP单元)。
由于整体架构分析空间较长,这里就不介绍NVIDIAAda架构的其他新特点了。文末将以附录的形式进行解释,感兴趣的用户可以翻到最后。
四是测试平台简介。
首先,我们来介绍一下测试平台。为了保证显卡RTX4070TiGAMINGOC的性能,我们的平台再次全面更新。
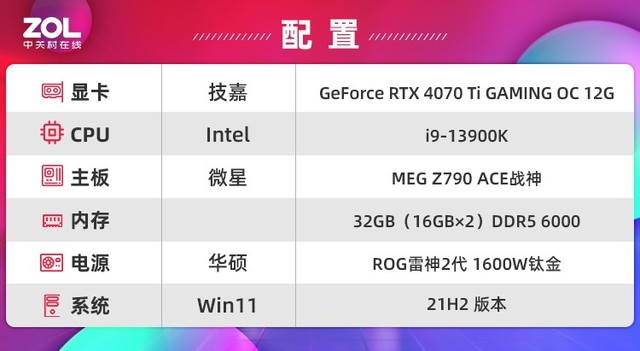
该测试平台的处理器采用了Intel最新的13代i9-13900K,其性能绝对强大,并在电源和显示器上进行了重点升级。
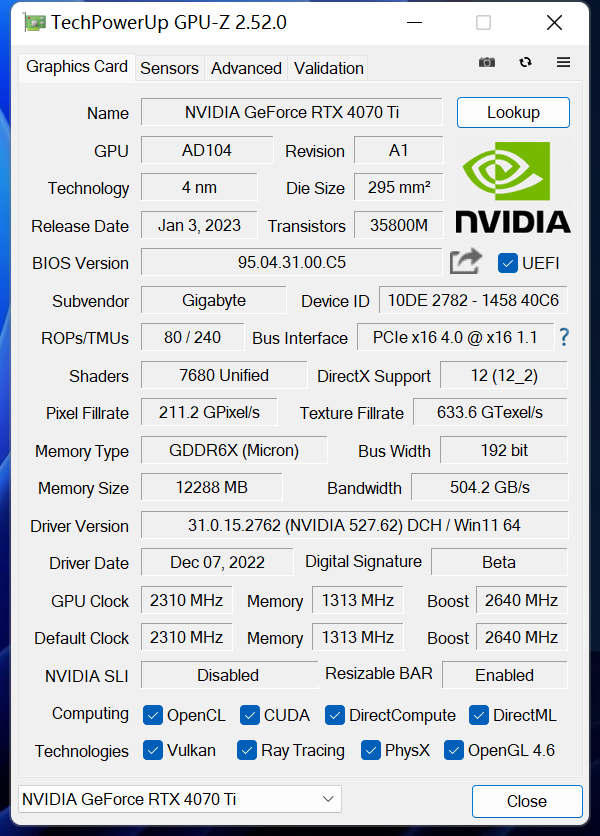
首先看看GPU-Z的参数,RTX4070Ti采用全新的AD104核心,拥有7680个CUDA,与之前曝光的RTX408012GB参数相同。与公版的2610MHz相比,本次测试的技嘉 RTX4070Ti GAMING OC Boost频率为2640MHz,有所提高。
采用12GBGDDR6XMicron显存的RTX4070Ti,位宽为192bit,显存带宽为504.2GB/s,光栅单元和纹理单元为80和240。
5理论性能测试。
以下是用来衡量显卡DX11理论性能的3DMARKFS套装FS,FSE,FSU三者分别对应于1080P,2K,4K的理论性能,取显卡分数的实际测试结果如下
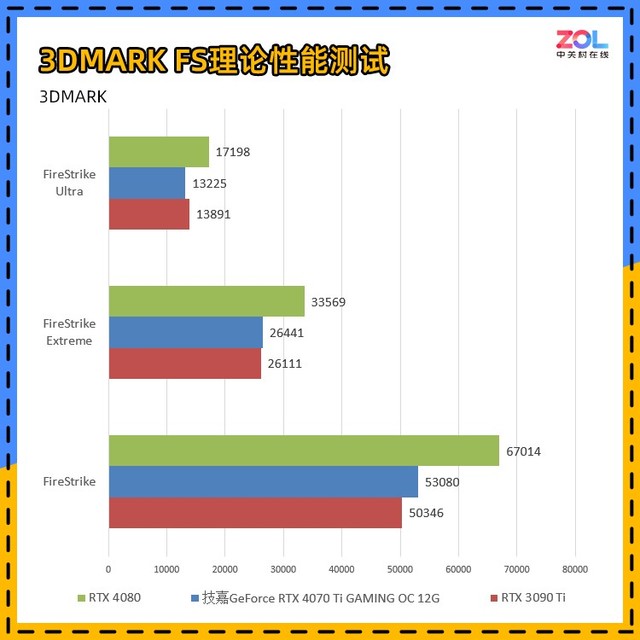
这里强调一下,在3DMARKFS测试结果中,i9-13900K存在BUG,GPU占用不足,导致分数较低;这里的FS结果是i9-13900K处理器关闭小核心测试的结果。
技嘉 RTX4070Ti GAMING OC主要与上一代旗舰RTX3090Ti相比,FS在显卡DX11性能的3DMARKFS套装测试中提高了5%;FSE提高了1%;FSU差距为5%,与RTX3090Ti相比,整体性能提高了3%左右。
与刚刚发布的RTX4080相比,综合成绩相差22%左右。
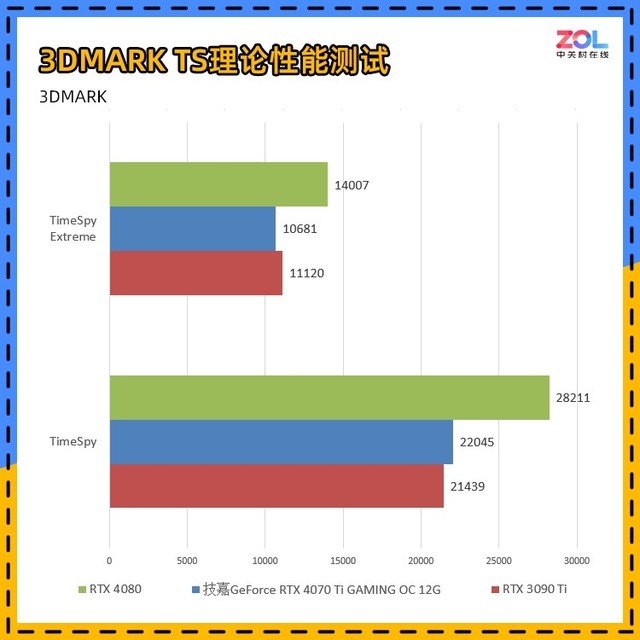
与RTX3090Ti相比,技嘉 RTX4070Ti GAMING OC在DX12环境下的TimeSpy和TimeSpyExtreme测试中的成绩分别为TS提高3%;TSE成绩差距约为4%。
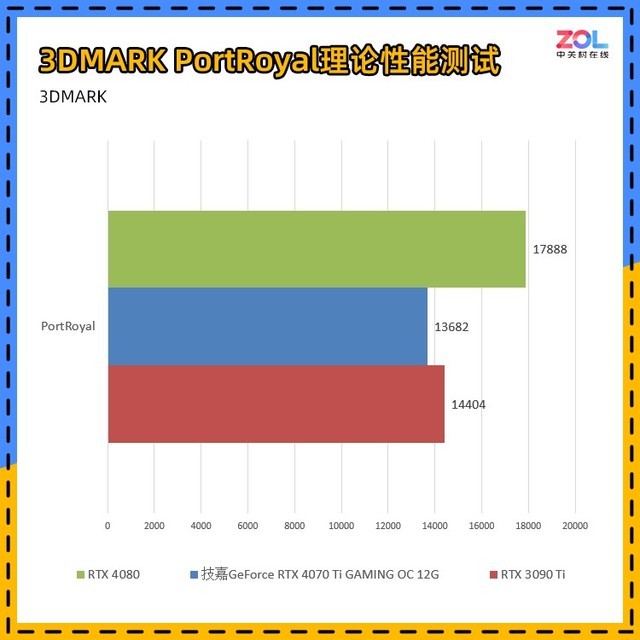
在3DMARK中,PortRoyal是专门针对光追性能的测试项目,与RTX3090Ti相比,技嘉 RTX4070Ti GAMING OC的分数差在5%左右,而RTX4080的分数差在24%左右。
总体而言,与RTX3090Ti相比,技嘉 RTX4070Ti GAMING OC在1080p和2K分辨率方面具有明显的优势,而在4K分辨率方面仍存在差距。
虽然RTX4070Ti的L2缓存已经达到了惊人的48MB,而RTX3090Ti只有6MB,但是高位宽高带宽的整体优势仍然很明显。

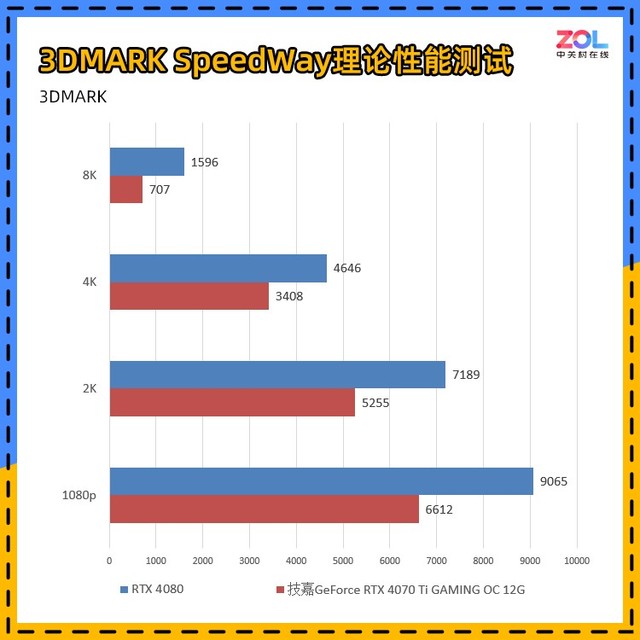
SpeedWay测试是用于测试DirectX12Ultimate性能的3DMARK最新更新的显卡基准测试。为了运行这个测试,显卡必须支持DirectX12Ultimate,并且包含6GB以上的显存。
该测试结合实时光跟踪和传统渲染技术来测量显卡性能。该场景包括光跟踪反射、实时全局照明、网格着色器、体积照明、颗粒和后处理效果。有趣的是,SpeedWay测试支持自由探索场景,可以检查照明和摄像头设置的变化如何影响视觉效果。
在这个测试中,我们比较了刚刚发布的RTX4080显卡,从1080p分辨率到8K的差距依次为:27%/27%/27%/56%。目前三种常见的分辨率差距几乎是一样的,但是下一个时代8K的超清分辨率绝对是用显存来说的。
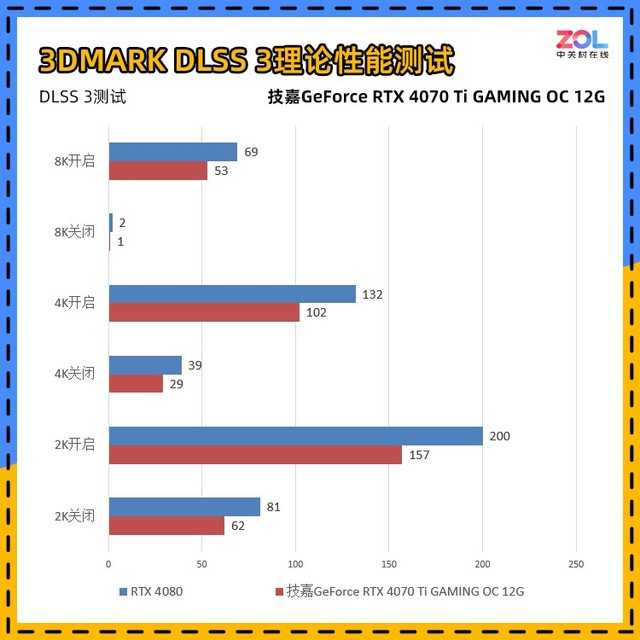
此外,我们还使用刚刚更新的3DMARKDLSS3进行了相关性能测试。与之前发布的RTX4080相比,两个显卡的差距一直保持在20%左右,除了在8K分辨率下关闭DLSS3的结果。
常规游戏性能测试6。
因为这次RTX40系加入了DLSS3新技术,所以以后还会单独测试,这里还是选择几款主流的3A大作进行游戏性能对比。
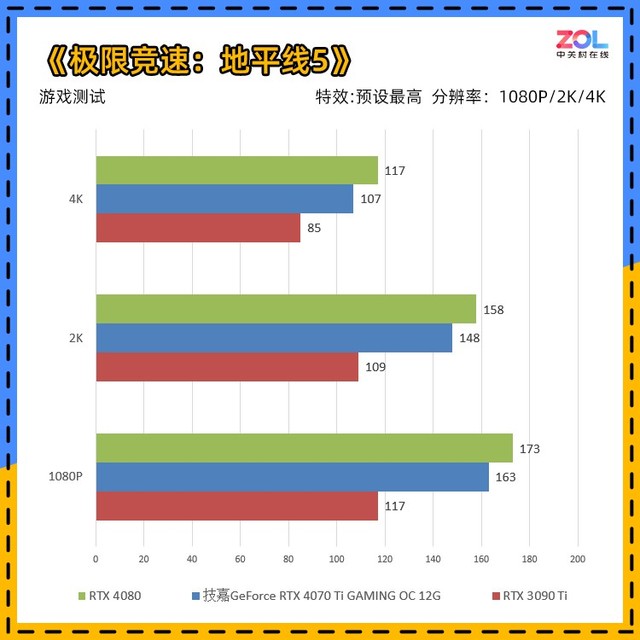
与RTX3090Ti相比,技嘉 RTX4070Ti GAMING OC的提升分别为1080p提升39%;2K提升36%;4K提升26%,综合提升34%。
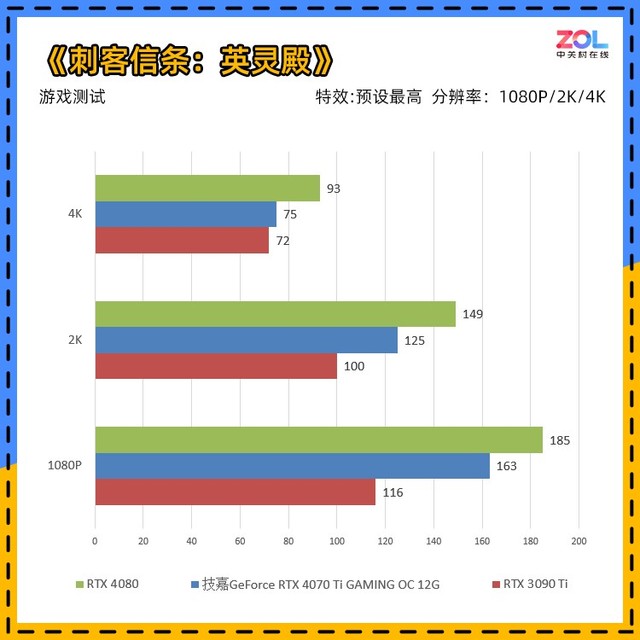
与RTX3090Ti相比,技嘉 RTX4070Ti GAMING OC在《刺客信条英灵殿》中的提升分别为1080p提升41%;2K提升25%;4K提升4%,综合提升23%。
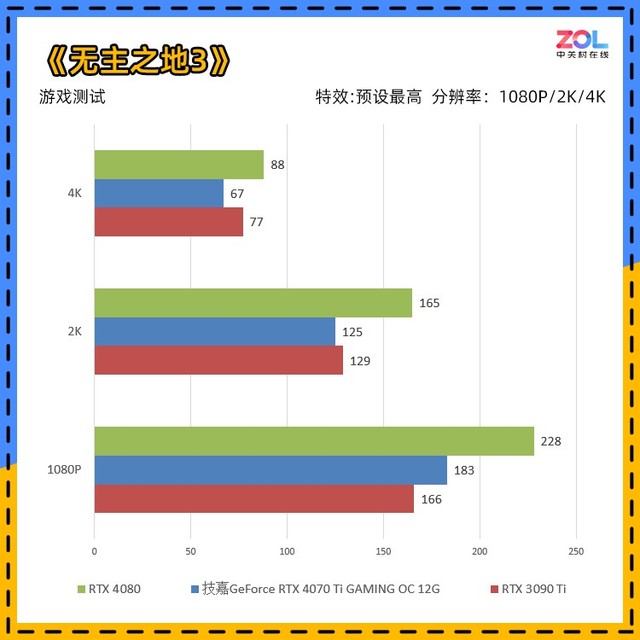
与RTX3090Ti相比,技嘉 RTX4070Ti GAMING OC的提升分别为1080p提升10%;2K相差3%;4K相差13%。
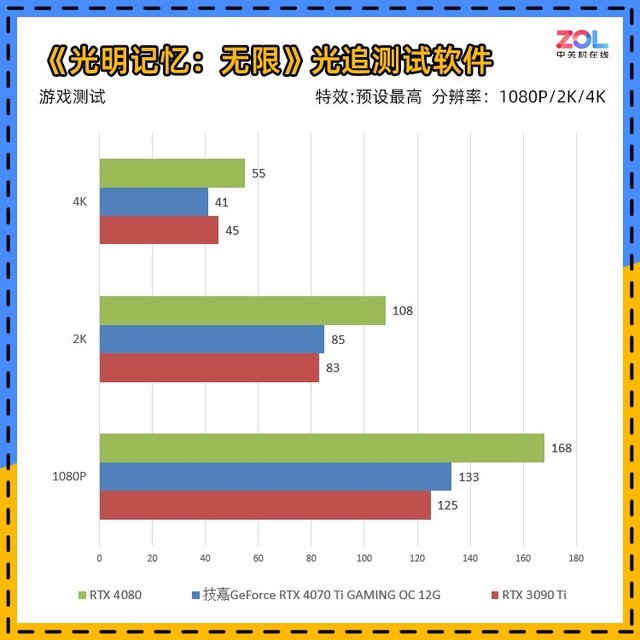
光记忆:无限光追测试软件是一种独立于游戏的测试工具,比游戏中使用的光追踪技术更多,测试条件为RTX最高/DLSS质量。因此,测试帧数相对较低,但实际游戏配置相当贴近百姓。
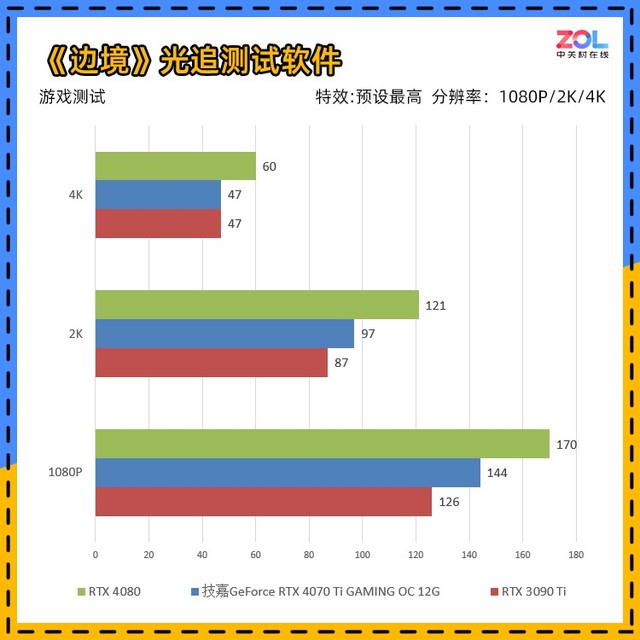
另一款国产游戏《边界》跑分软件中,情况与《光明记忆无限》基本相同,测试条件均为RTX最高/DLSS质量。
RTX4070Ti在常规游戏测试中不难发现,RTX4070Ti在1080p分辨率下可以有很大的优势,但是凭借24GB大显存和1000GB/s的带宽,RTX3090Ti在高分辨率下具有明显的优势。
因此,总的来说,RTX4070Ti实际上和RTX3090Ti一样强大,只是两个显卡的战场不同,但是RTX4070Ti在用户普遍使用的1080p和2K分辨率方面有更大的优势,更不用说它还能打开DLSS3这个神奇的技能了。
性能测试7DLSS3。
目前已有35多款游戏和应用程序宣布支持DLSS3,其中15款已上市。目前支持DLSS的游戏和应用有250多款,而且还在逐月增加。
11月15日,有13款游戏加入DLSS3,包括《逆水寒》、《微软模拟飞行》、《毁灭全人类2重新探测》、《瘟疫传说安魂曲》、《光明记忆无限》、《暗影火炬城》、《F122》、《生死轮回》、《漫威蜘蛛侠重制版》、《超级人类》等。最近发布的是《WRCGenerations》、《最佳飞车不羁》、《战锤40K暗潮》
以下就让我们来实际测试一下,拥有一款全新的DLSS3游戏,可以达到什么帧率。

这次DLSS3的测试图表比较繁琐,而且增加了1%LowFPS和延迟测试,普通FPS很容易理解,那么这个1%LowFPS是什么意思呢?
首先,游戏benchmark通常测试的FPS是一段时间内的游戏平均帧。另一方面,1%LowFPS将一段时间内的帧数从大到小排列,取出最小的1%,然后寻求1%的平均值。
其实简单来说,这两个值并不代表我们玩的时候会有什么感受,但是FPS更注重整体,而1%LowFPS则是从最差的那一刻寻求平均值,更加谨慎。

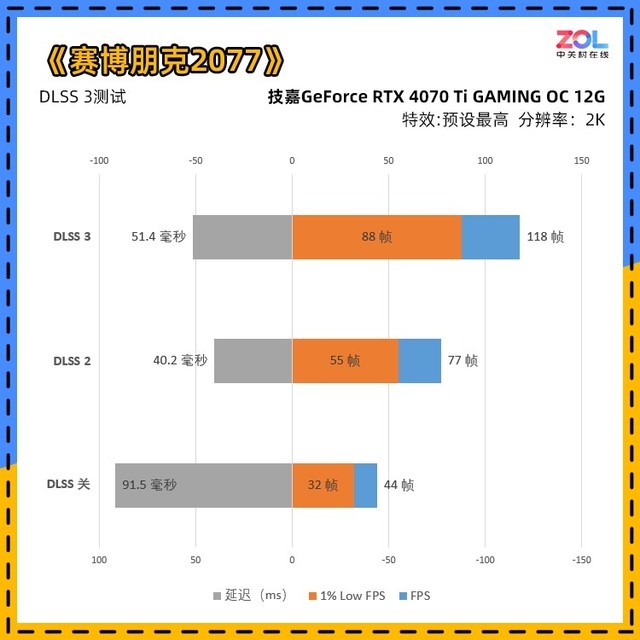
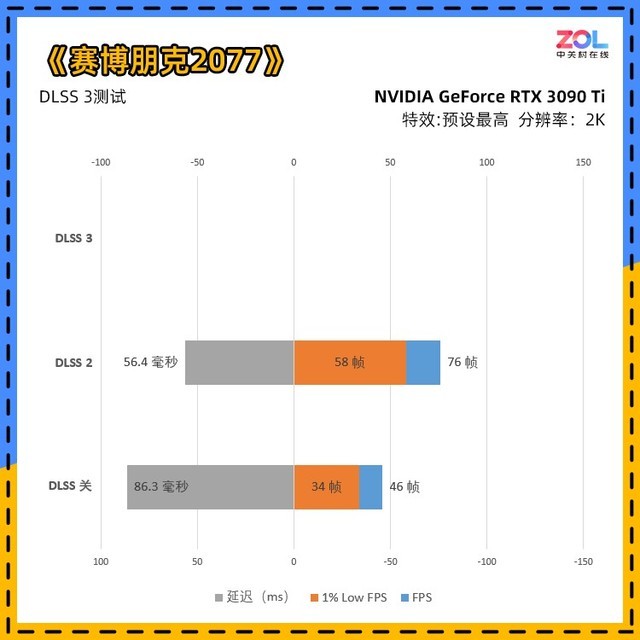
看完1%LowFPS,我们再来看看这张图。坐标轴左侧的是延迟(越低越好),坐标轴右侧的是帧数(越高越好),两侧的值可能会因为涉及正负坐标而有所不同。
在《赛博朋克2077》中,RTX4070Ti定位于2K分辨率下的电竞级帧率,数据反映得比较真实稳定,可以看出,即使技嘉 RTX4070Ti GAMING OC显卡在DLSS关光线追踪最高的情况下,也只有44帧,而且延迟达到91.5毫秒。DLSS3打开后,帧数为118。
与RTX3090Ti相比,尽管RTX4070Ti在关闭和DLSS2模式下的分数几乎相同,但是如果RTX4070Ti打开DLSS3,增长率将达到55%左右,这是非常大的。

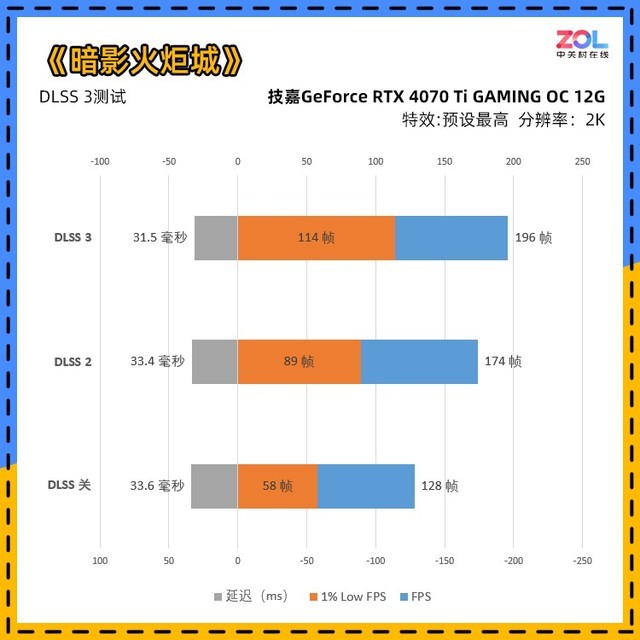
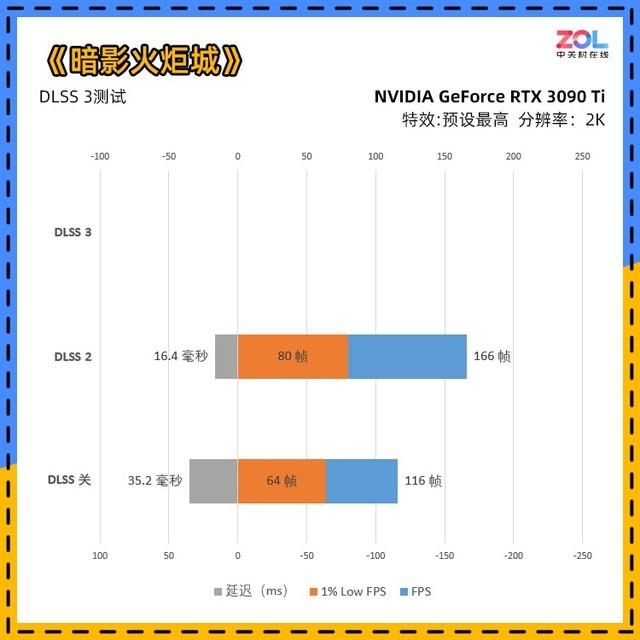
在打开光追之后,《暗影火炬城》对性能的要求有了明显的提高。RTX4070Ti与RTX3090Ti相比,在不打开DLSS3的情况下,RTX4070Ti几乎具有10帧的领先优势。打开DLSS3后,增长率约为18%。

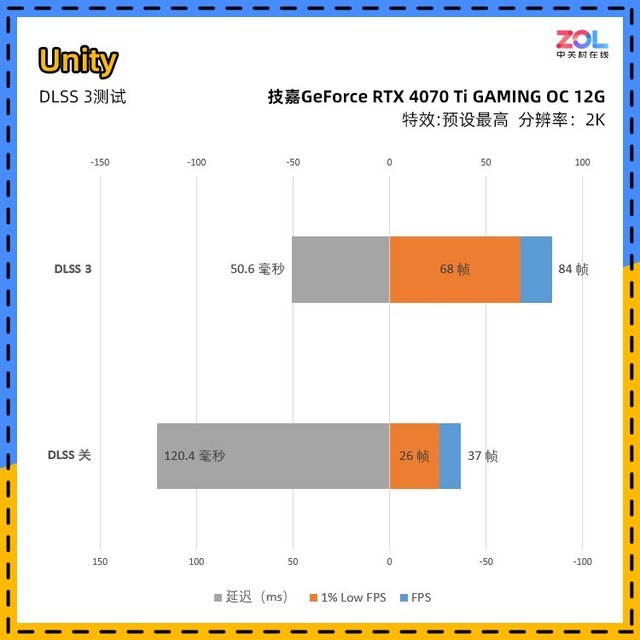
我们将通过FrameView记录整个过程,在Unity的测试软件中自动播放一段即时演算视频。但是由于程序只提供关闭和开启DLSS3的操作,所以我们取两组分数。
可以看出,在DLSS3关闭之后,即使在2K分辨率下,平均FPS也有37帧,延迟也高达120.4ms。而且打开DLSS3之后,提升很大,性能提升到127%,演示效果肉眼可见。

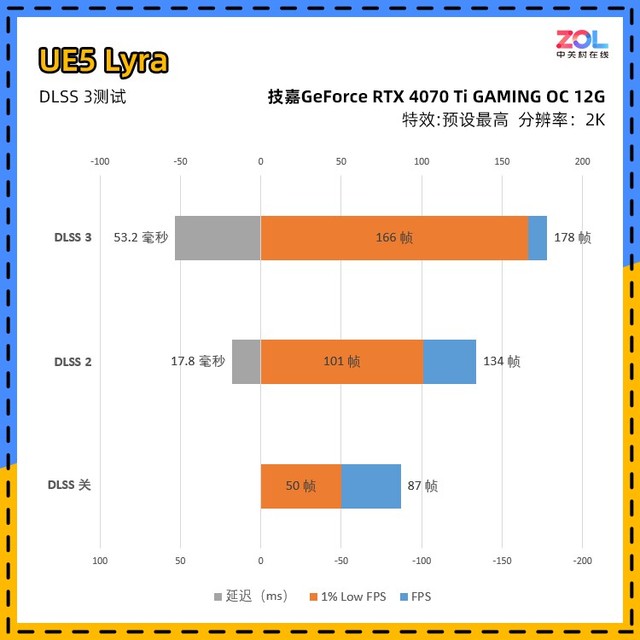
在UE5提供的测试游戏中,DLSS的快速测试很方便,分为DLSS关(超分辨率关+帧生成关+Reflex关);DLSS2(超分辨率性能+帧生成关+Reflex开);DLSS3(超分辨率性能+帧生成开+Reflex开)三级测试。
在这个对比中,由于场景有限,我们选择了固定镜头测试,因此三组数据的1%Low帧数相对较高。

当然,对于画质,我们也进行了测试。在上图中,我们截取了《赛博朋克2077》中的一个角落。我们可以看到,在两种DLSS模式下,与原始画质相比,几乎没有明显的变化,只有栅栏处的光影效果不同,但这个缺陷几乎可以忽略不计。
8生产力工具测试。
尽管RTX4070Ti是一个彻底的游戏卡,但是我们还测试了一些软件,如渲染和编码。
Blender。
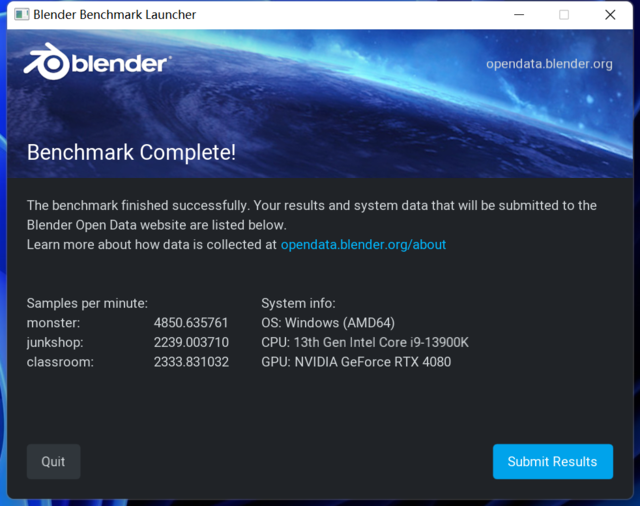
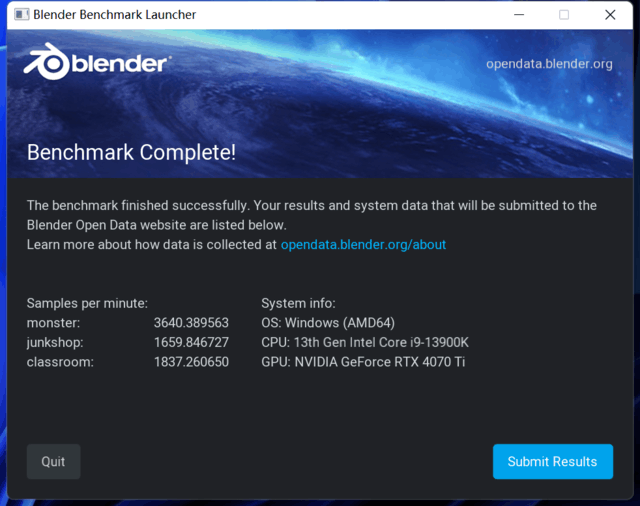
Blender是一个专业的3D渲染软件,这次推出了一个固定的benchmark跑分软件,省去了安装软件下载材料的麻烦。这个跑分软件只需要下载启动程序,软件就会自动渲染测试monster/junkshop/classroom的三个场景。
RTX4080显卡得分分别为4850/2239/2333分,平均为3141分;下图为技嘉 RTX4070Ti GAMING OC显卡得分分别为3640/1660/1837分,平均为2379分。这两张显卡的性能差距约为32%。
Resolve_18.0.2DaVinci_。
接下来,我们通过达芬奇测量NVIDIAAV1编码,将H.264编码与输出进行对比。输出尺寸为4KUHD,质量选择最好,看看两组成品的区别。
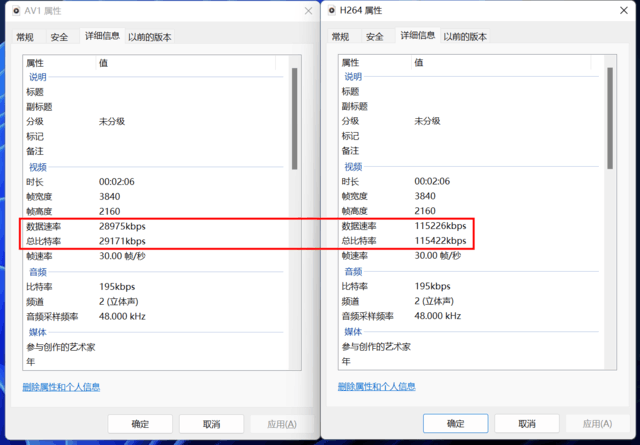
在这次RTX4070Ti测试中,我们重新编码和渲染了这种材料,但是最后的渲染时间也是1分50秒左右,几乎和RTX4080一样。
AV1生成的视频码率较低,几乎是H.264的三分之一,因为我们没有固定码率,而是选择了相同的画面质量。
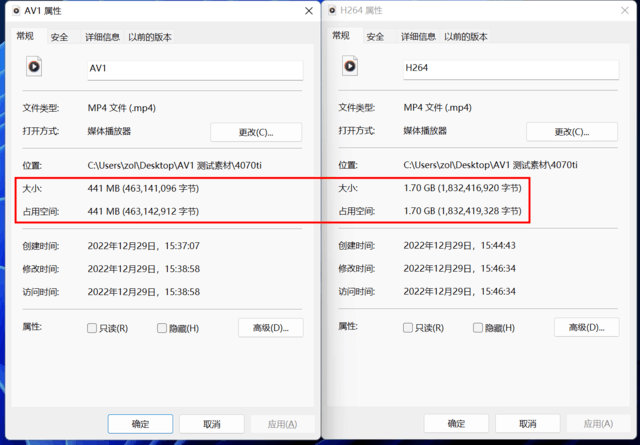
而且低码率也意味着视频体积越小,该视频采用AV1编码的大小是H.264编码的四分之一,对于硬盘空间的节省十分明显,下面就来看看这两个视频的画质表现。
左边的AV1右H264(点击查看大图)
我们选择NVIDIA的ICAT软件进行分屏比较。首先,从较低的缩放倍率来看,两个视频在颜色和清晰度上是完全相同的,放大500%后可以看到噪声。AV1编码像素过于光滑,几乎没有明显的颗粒感,使得场景看起来更加干净。
9温度和功耗测试。
在功耗测试中,我们选择FurMark软件进行复制测试,并采用GPU-Z测试温度,功耗仅计算显卡本身。

技嘉 RTX4070Ti GAMING OC显卡在半小时的复制过程中,峰值温度控制在60℃左右,热点温度只有70℃左右。如果TDP达到100%,可以看出整卡功耗在283W左右,而TDP则在285W左右。
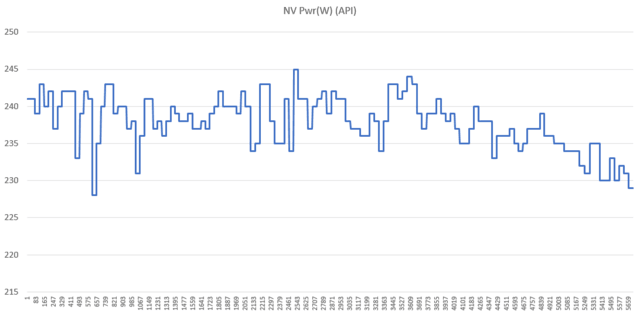
值得注意的是,这次我们在复制机测试中,尽管最大板载功耗约为285W,TDP达到99%。但是在实际的游戏测试中,大多数3A游戏只有220W左右,甚至有些游戏没有消耗性能。
在这里,我们选择了最消耗性能的赛博朋克2077,它记录了benchmark在4K分辨率下的光追超级预设全过程的功耗。表格左侧为功耗,下方为当前帧。
可以看出,RTX4070Ti在功耗峰值点只有245W左右,而在整个benchmark测试中,平均功耗为238W。因此,在实际使用过程中,由于不同的游戏负荷不同,GPU的实际功耗是动态变化的,RTX40系列很难触及功耗墙,就像FPS随时间变化一样。
RTX3090Ti10对标。
与RTX4080相比,这次发布的RTX4070Ti确实存在着很大的差距,如果像以前所说的RTX4080一样,只区分显存名称,对大多数用户来说确实有点混乱。
而且这个RTX4070Ti的发布终于与上一代RTX30系显卡有了交集,之前发布的4080和4090都属于吊打上一代产品。

与RTX3090Ti的上一代旗舰相比,这张卡的亮点部分是RTX3090Ti,从整体测试来看,RTX3070Ti在1080p和2K分辨率方面具有很大的优势,但是在4K分辨率下,RTX3090Ti将会带回一座城市。
但是RTX3090Ti本身的定位就是生产力工具,24GB的大显存高带宽都是帮助更好的内容创作。因此对游戏玩家来说,即使购买RTX3090Ti追求极致性能,显存也是浪费了一半以上。
RTX4070Ti是中高端游戏卡的定位,而2K@144Hz已被认为是目前比较先进的显示规格,这张卡完全可以控制,再加上DLSS3这样的神技,在4K分辨率下上百帧也是值得的。
对广大3A玩家而言,这款RTX4070Ti绝对是性能的选择,甚至是性价比的选择。归根结底,9499元的RTX4080在性能上比RTX4070Ti要好得多,但是3000元的差价足以让任何人反复考虑。
而且与RTX3090Ti相比,虽然输入4K分辨率,但并非全面超越。但是价格优势同样明显,一款6499元的RTX3090Ti你不动心吗?
最终,RTX4070Ti显卡的销售时间比性能解禁时间晚一天,为1月5日22:00,感兴趣的用户不妨关注一下。
11附录1-NVIDIAAdaLovelace架构分析。
重新排序ShaderExecutionReordering(SER)着色器。
SER的主要功能是提高着色器的性能,可以将低效的工作负荷动态重组为更高效的工作负荷。光跟踪的性能主要得到了很大的提高。
简单来说,GPU在执行类似工作时效率最高。然而,随着光追效果的增强,每个场景中可能会有数百万盏光线照射在不同的材料上,我们知道不同材料的反射率和反射效果是不同的。因此,为着色器创造了大量低效、发散的工作负荷。
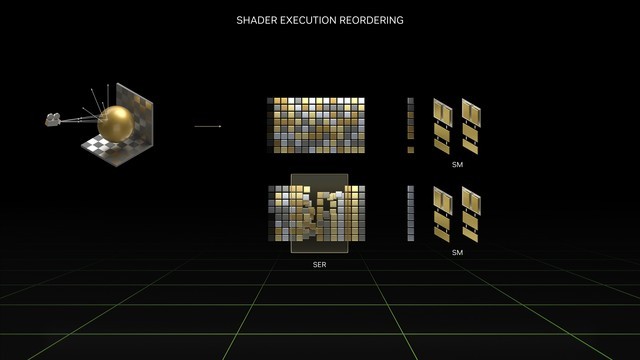
SER可以将这些杂乱的指令重新分类,并将其动态重组为更高效的工作负荷。根据NVIDIA的说法,SER可以将着色器的性能提高两倍,并将游戏帧率提高25%。
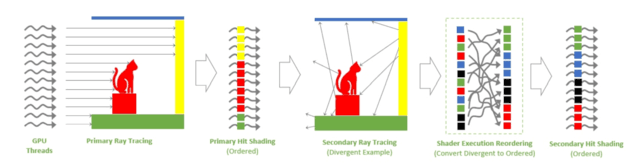
举个简单的例子,当光线第一次从发射端到碰撞端是非常规则的射线,而碰撞物体后的二次光追会有大量的发散和不规则的反射,这对于光追负荷来说是非常高的。从图中可以看出,SER可以对这些指令进行二次排序,以充分发挥着色器的最大性能。
但幸运的是,如此实用的功能并非RTX40系的专利,而是一款易于集成的SDK,目前需要游戏开发者将其集成到游戏中。此外,由于它是一种通用的逻辑,后续也可以直接集成到Windows的API中,这样游戏开发者就可以直接调用系统API,而无需特别引用。

可以说,SER对于手持RTX20系及以上(可以打开光线追踪)的N卡用户来说是一大福音。毕竟谁不喜欢免费提升的光追性能呢?
RTCores的第三代。
RTCore的作用在于更快的光跟踪计算能力,如果说在RTX30系显卡中,想要享受4K高帧率游戏有点困难,那么RTX40系显卡就会显得轻松。
显卡上的GeForceRTX4090已经达到了191RT-TFLOPs的处理能力,而RTX30显卡的最快处理能力是78RT-TFLOPs的2.4倍。据NVIDIA官方称,与上一代相比,第三代RTCore的峰值RT-TFLOPs增加了2.8倍。而且这只能说明,这个4090并不是AdaLovelace架构的最终形式。
Micro-MapEnginesOpacity。
两个重要的硬件单元被引入到第三代RTCores中,首先是OpacityMicro-MapEngines,可以理解为微映射透明引擎,它的主要功能是优化光线跟踪渲染,可以大大减轻着色器的工作负担。
例如,不同的光线会影响叶片等复杂物体的表现状态和叶片之间的光线反弹,因此光线跟踪的计算量是巨大的。
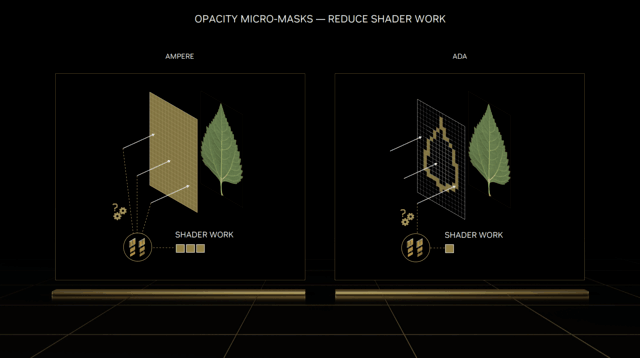
然而,OpacityMicro-MapEngines可以将光跟踪特性烘焙到不透明的蒙版中,因此那些形状不规则、半透明的物体,也可以更快、更准确地渲染出来,从而大大减轻着色器的工作负担。
DisplacedMicro-MeshEngines(DMM)
DisplacedMicro-MeshEngines可以理解为微网格置换引擎,它构建了BVH(Boundingvolumehierarchy)的光跟踪速度提高了10倍!使用的显存减少了20倍!

DMM由第三代RTcore处理。与前几代相比,它只使用基本的三角形渲染复杂的几何图形,大大降低了存储和处理的需要。
具体的工作原理从图中一目了然。新的DMM可以简化大量复杂的图形,创建简单的模型,但整体光线跟踪效果不变。

通过一些模型数据,我们可以具体看到新的DMM简化了多少模型。经过简化,原来1100万三角面的模型只有15万左右的微网格,BVH的构建速度提高了8.5倍,小了6.5倍。
这还不是最夸张的。模型越复杂,优化效果越好。在这些官方比较示例中,速度最快可以提高15倍以上,容量可以简化20倍。
TensorCores第四代。
第四代张量核心的升级除了光追单元的升级外,更加恐怖。采用新型FP8张量引擎,在GeForceRTX4090显卡上,吞吐量达到1.32TensorpetaFLOPs,增加了5倍。
请注意这里的单位——petaFLOPs。以前的TFLOPs是万亿次浮点运算,而petaFLOPs则是千万亿次浮点运算。
DLSS3。
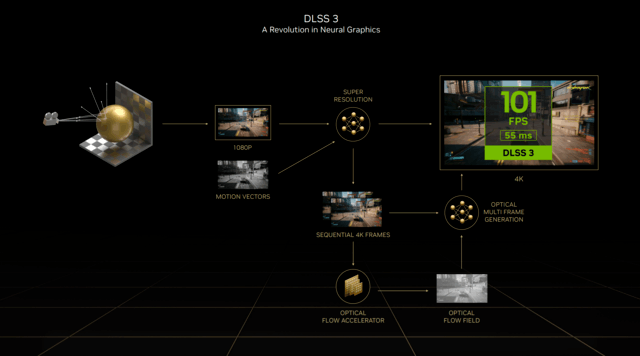
这次推出的DLSS3也是RTX40系列的一大卖点,从DLSS2.3直接进入DLSS3版本,也可以看出这次的升级很大。NVIDIA官方称DLSS3为神经网络渲染新时代。
在原有DLSS超分辨率的基础上,全新的DLSS3增加了光学多帧生成技术,以生成全新的帧,而不是像原来那样只能生成像素。
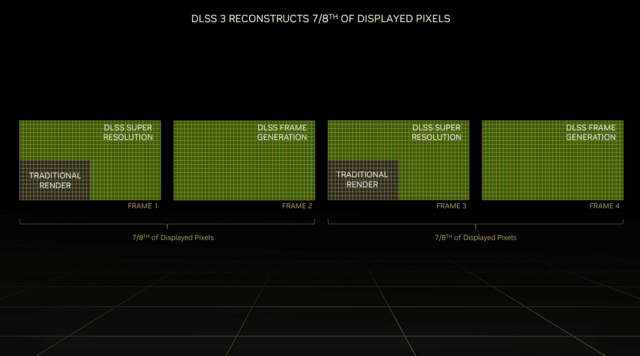
结合DLSS超分辨率、DLSS帧生成和NVIDIA Reflex三大技术,DLSS3可以重建八分之七的像素,大大提高性能。
DLSS2可以将帧率提高2倍,DLSS3可以在GPU受限的游戏中提高4倍,例如2K分辨率及以上的更高分辨率。
这一次,DLSS3跨越了一个大版本,在思路和原理上再次升级。我们可以简单地解释一帧完全猜测的技术,但实施需要大量的推理和计算,以及绝对先进的想法。
然而,凭空产生的一帧,在延迟方面肯定高于DLSS2。因此,NVIDIA Reflex被捆绑在这个完整的DLSS3中,可以有效地帮助减少延迟。

NVIDIA给它起了一个神经网络渲染新时代的名字。纵观目前市场上的XeSS和FSR技术,DLSS绝对可以称得上是巨人的肩膀。当然,经过多年的创新,手持上一代显卡的玩家遭受了痛苦。目前唯一的办法就是买一张RTX40显卡,体验DLSS3的帧生成。
NewOpticalFlowAccelerator。
在第四代TensorCores中,最新引入了NewOpticalFlowAccelerator光流加速器,这就是为什么DLSS3中的帧生成为RTX40显卡的专属。
在原DLSS2的基础上,光流加速器还可以计算两个连续帧中的光流场,从第一帧到第二帧捕捉游戏画面的方向和速度,捕捉粒子、反射和光照等像素信息。并分别计算运动矢量和光流,以获得精确的阴影重建效果。

以《赛博朋克2077》为例。在第一帧中,光流加速器会捕捉到粒子、反射和光线等信息。并在第二帧中找到匹配的像素区域,计算帧之间的差异。
假如DLSS2可以猜测一张图片中剩下的像素,那么DLSS3除了这些,还可以猜测下一帧的图片。

此外,由于DLSS3的帧生成是在GPU中处理和运行的,AI也可以提高帧率,即使遇到CPU瓶颈的游戏。这就是为什么DLSS3可以突破CPU的限制来提高帧数。
双AV1编码器。
这次升级的第八代NVENC编码器可以说是直播、视频和后期工作者的一大福音。第一次增加了对AV1编码的支持,最明显的效果就是直播。
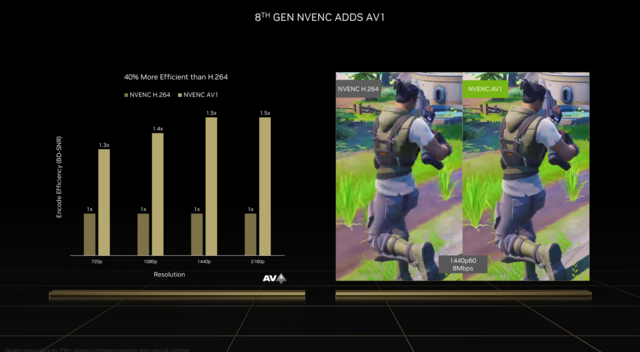
与传统的H.264编码相比,AV1编码的平均效率提高了40%,AV1编码的画质在相同的代码率下会更好。当前,大多数直播的分辨率和清晰度都受到平台规定的最大比特率的限制。例如,Twitch限制的8Mbps,可以看到AV1编码的清晰度明显高于H.264的画面,同样是2K60帧。
说起直播,OBS相信大家都很熟悉。在10月份即将发布的补丁中,OBS增加了对NVENC的AV1编码支持。
自然,直播只是我们更容易看到的AV1优势,AV1编码在视频工作的各个环节都能带来很大的提升。
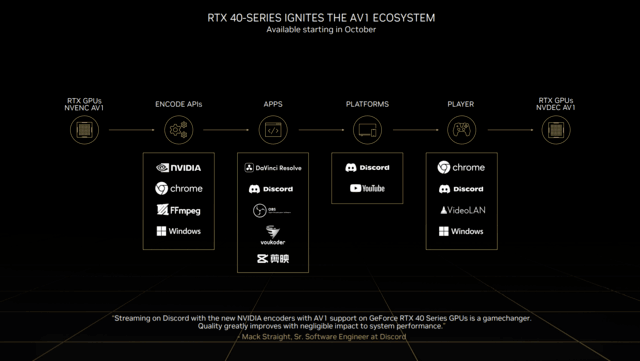
因此,如图所示。NVIDIA从编码API、软件、平台到播放器,为广大用户铺就了一条完整的生态链,将全面支持AV1编码。
另外,NVIDIA一直强调的双AV1编码。顾名思义,一些显卡配备了两个编码器,其效果也很明显。
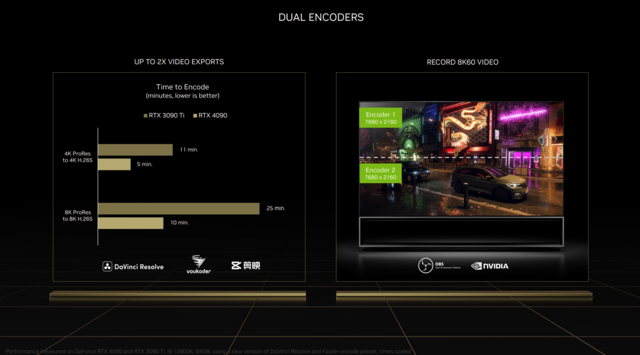
第一,根据官方宣传,RTX4090在4KH.265的导出速度上是RTX3090Ti的2.2倍;在8KH.265的导出速度上,RTX4090是RTX3090Ti的2.2倍;在8KH.265的导出速度上,RTX4090是RTX3090Ti的2.2倍;
8K60帧的视频录制除了导出速度之外,在过去几乎是不可想象的,而双编码器的优点是可以将图像分成两部分,两个编码器可以分别处理7680×2160的图像信息,最后完成拼接。
至于编码部分,大部分用户可能感受不深,但是有一天,当你想录屏的时候,你会发现显卡不支持,你会发现它的重要性...
随着图像逐渐进入超清时代,硬件编码和渲染几乎成为不可或缺的帮手。虽然硬件编码在质量上还不如CPU软件编码,但软件编码已经达到了极致的画质,需要无限的时间。即使在一张8K渲染图中,两种编码方式的时间差距也已经达到了几个小时,除了一个10秒的CG动画。在不断进步的硬件编码中,质量和时间也在不断受到挑战和刷新。
12附录2-AdaLovelace是谁?
作为英国数学家和计算机程序的创始人,AdaLovelace(1815-1852)建立了循环和子程序的概念,被称为世界上第一个程序员。
Ada从小就有很高的数学天赋,她的父亲称她为平行四边形公主,后来她的合作伙伴CharlesBabbage称她为数字女巫。19岁时,Ada嫁给了她以前的科学家庭教师,婚后她对数学充满热情。

从1842年到1843年,翻译Babbage的《分析机概论》备忘录花了9个月的时间,写了许多笔记,其中给出了用计算机解决Bernoulli数量的详细说明。因此,Ada被广泛认为是世界上第一个程序员。
而且以她的名字命名的语言——ada语言,已成为美国军方开发战斗机等尖端武器的语言。
从几行简短的生活介绍中,不难看出,虽然Ada的生活只经历了37个短暂的春秋,但却足以被后人铭记。
正因为如此,在NVIDIARTX40的先行宣传中,使用了以未来敬传奇的slogan。
技嘉魔鹰GIGABYTE AORUS RTX4070TI Gaming OC 12G 电竞游戏设计智能学习电脑独立显卡支持4K
[经销商]京东商城
[产品售价]¥6999元
Tag:技嘉 RTX4070Ti




