
白色整机是目前DIY用户更偏爱的类型,从白色主板、显卡到机箱,今天为大家再带来一款白色显卡的评测,技嘉 RTX4070雪鹰。

RTX 4070显卡NVIDIA官方给出的定位是,在开启光追和DLSS的情况下,3A游戏达到2K百帧及以上的水准。而且根据首测的成绩来看,它相比RTX 3070 Ti性能提升20%左右,与RTX 3080不分伯仲,并且在光追及DLSS方面要领先RTX 30系显卡。
目前RTX 4070在电商中依然有大量原价卡在售,在RTX 40系中属于比较有性价比的产品,下面先来看看这款技嘉 RTX4070雪鹰的外观。
1 技嘉 RTX4070雪鹰概览
本次技嘉 RTX4070雪鹰的包装非常简洁,除了NVIDIA规范的型号区域,整体以纯白色为主,系列名称AERO居左,并且采用了比较有设计感的字体。


配件部分,由于技嘉 RTX4070雪鹰仍然采用了单16pin供电,所以包装内附赠了8pin*2的电源转接线。不过本次RTX 4070的功耗并不大,已经有不少AIC推出了单8pin供电版本。

技嘉 RTX4070雪鹰显卡的整体尺寸为300×130×57.6mm,卡身整体为纯白色,正面导流罩,在风扇区域覆以拉丝工艺的金属外甲。虽然两种材质截然不同,但无论从色系还是质感,却有意外地和谐。

技嘉 RTX4070雪鹰在风扇正上方印有“CREATIVITY STARTS HERE”字样,意为“创造力从这里开始”。显卡采用风之力散热系统,拥有三个9cm风扇,支持智能启停并且采用正逆转设计。
而内部采用铜板直接接触GPU,搭配8根复合式热管,提供更高的导热效率。

技嘉 RTX4070雪鹰的背板整体采用了裸色金属,并且在尾部拥有大面积镂空进气格栅,能够看到PCB只有显卡整体的一半左右。

本次技嘉 RTX4070雪鹰的整卡功耗为215W,采用单16pin的辅助供电。
需要注意的是,目前适用于RTX 30系列的12pin接口和电源转接器与RTX 40系列显卡不兼容。

视频输出接口上,依旧采用了HDMI 2.1 + DP 1.4a*3的四接口设计。HDMI 2.1可支持4K 120Hz HDR、8K 60Hz HDR。
2 NVIDIA GeForce RTX 4070 架构浅析
本次发布的GeForce RTX 40系显卡由全新的NVIDIA Ada Lovelace架构打造,采用TSMC 4N NVIDIA定制工艺,旗舰核心AD102达到了恐怖的760亿个晶体管,而在RTX 30系显卡中为280亿个。
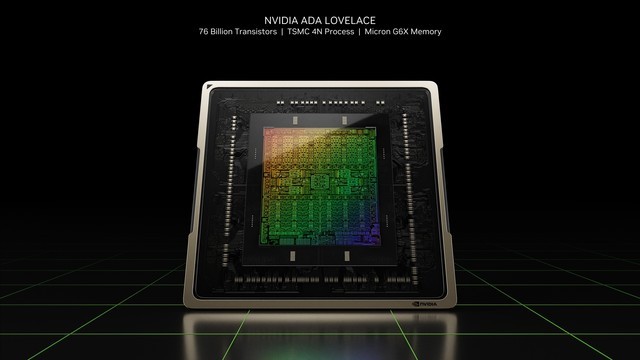
与上一代NVIDIA Ampere相比,NVIDIA Ada Lovelace在相同功率下,具有2倍以上的性能提升,最高可达到90-TFLOPS的着色器数据吞吐量。
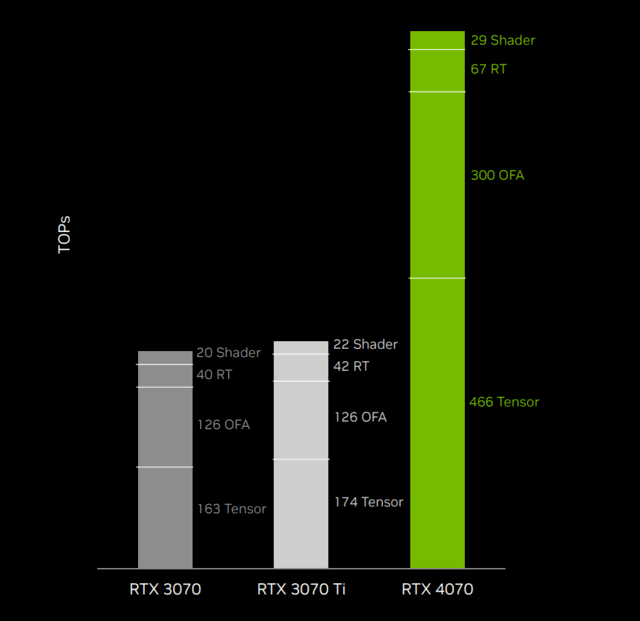
本次发布的RTX 4070共有5888个CUDA核心,提供了29-TFLOPS算力;46个第三代Ada RT Core拥有67 RT-TFLOPS;184个第四代Tensor Core可提供466 Tensor-TFLOPS。
其实如果只对比传统的光栅性能,RTX 4070的进步并没有很大,但在AI逐渐发展的今天,需要大量逻辑推理运算,所以可以看到相比30系的Tensor算力,几乎达到2.7倍的提升。
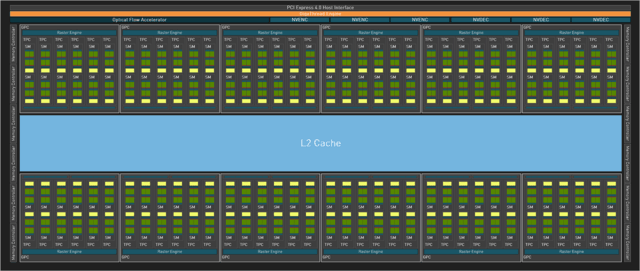
完整的AD102核心
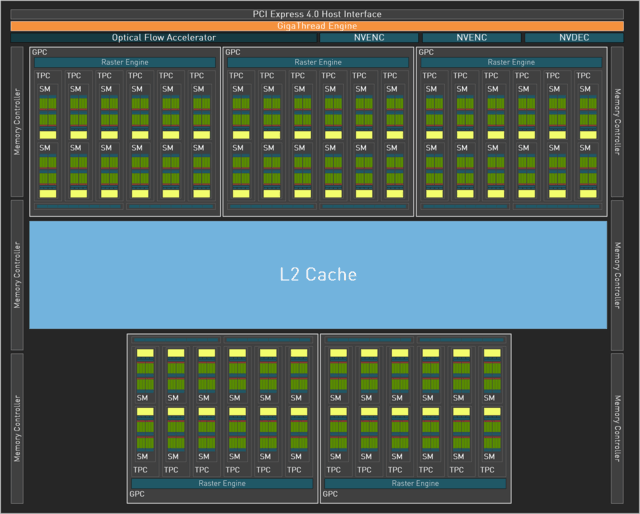
RTX4070Ti使用的AD104核心
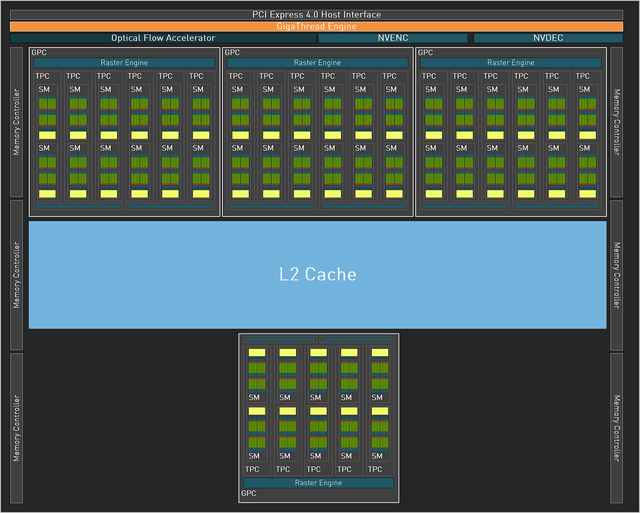
RTX 4070使用的AD104核心
本次RTX 4070使用了AD104芯片,采用了4组GPC,其中1组少了1组TPC,并且NVENC单元变为2个。
另外可以看到本次RTX 40系显卡的L2缓存都占比较大,其实也是有意为之。
这张RTX 4070的L2缓存为36MB,而上一代RTX 3070 Ti为4MB,达到了9倍的差距。增加L2缓存的大小可以提高性能,降低延迟,并提高续航时长,数据访问在GPU上即可完成(否则GPU就要频繁从显存读取数据,过分依赖显存带宽)。所以,这也是为什么在RTX 40系显卡中,位宽带宽普遍偏小的原因。
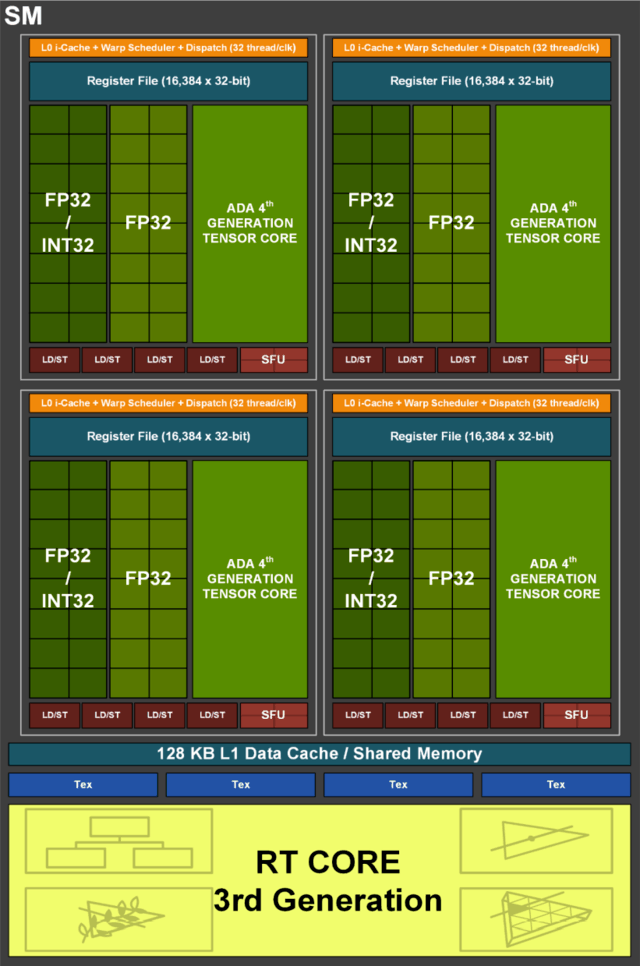
其实根据完整的架构图就能看出,此次Ada架构整体结构性的改动并不大,这一点从SM单元便能清晰印证,同样的FP32 CUDA核心,同样的FP32/INT32混合CUDA核心,同样的L1级缓存等等。当然,每个SM单元内部的Tensor Core升级为第四代。

不过变化最为显著的,则是第三代光追核心,我们结合两代架构来看。在第二代光追核心中,包含负责边界交叉测试的Box Intersection Engine引擎,和负责三角形交叉测试的Triangle Intersection Engine引擎。

而在第三代光追核心中,还增加了两个新的引擎:Opacity Micro-Map Engines(OMM)和Displaced Micro-Mesh Engines(DMM),这两个新的硬件单元可以极大地提升光追性能(具体原理后文详细介绍)。
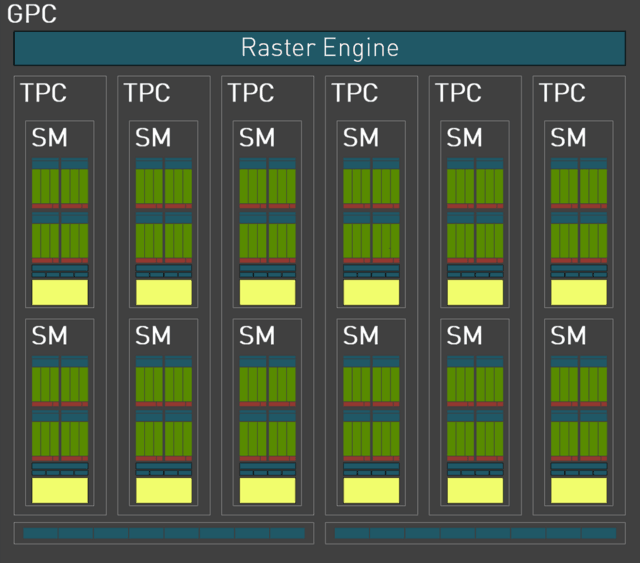
至此,每2个SM单元组成一个TPC单元,每6组TPC单元组成一个完整的GPC顶层单元(在部分核心中,会出现5组TPC组成一个GPC单元的情况)。
而每个GPC单元又搭载一个独立的光栅引擎、两组ROP分区(每组包含8个ROP单元)。
由于整体架构分析篇幅较长,关于NVIDIA Ada架构的其他新特性就不在这里介绍了,将在文章末尾以附录的形式展开说明,有兴趣的用户可翻至最后。
3 测试平台简介
首先介绍一下测试平台,为了保障技嘉 RTX4070雪鹰的性能发挥,我们的平台也进行了全面更新。
下面看一下最新版的GPU-Z信息,RTX 4070采用AD104核心,拥有5888个CUDA,而此前测试的RTX4070Ti为7680个CUDA,在同系列显卡中,CUDA数量其实比较能反应性能强弱,所以简单算一下RTX 4070的性能大概相当于RTX4070Ti的77%。
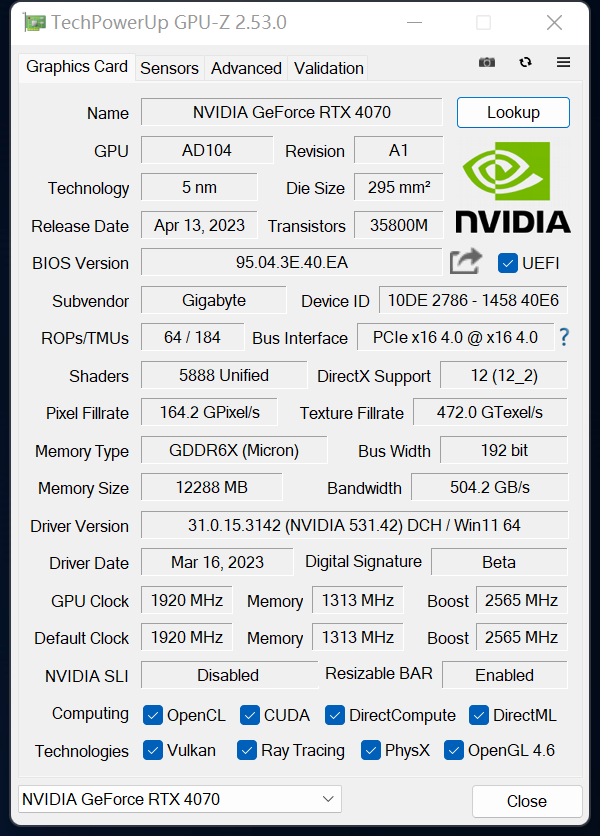
技嘉 RTX4070雪鹰的Boost频率为2565MHz,公版RTX 4070的Boost频率为2475MHz。
采用12GB GDDR6X显存,位宽为192bit,显存带宽达到了504 GB/s,光栅单元和纹理单元为64和184。
本次测试平台的处理器采用了Intel最新的13代i9-13900K,性能绝对强悍,并且电源和显示器上进行了着重升级。
4 理论性能测试
下面先进行的是用来衡量显卡DX11理论性能的3DMARKFS套装:FS,FSE,FSU三者分别对应显卡在1080P、2K、4K的理论性能,取显卡分数实际测试结果如下:
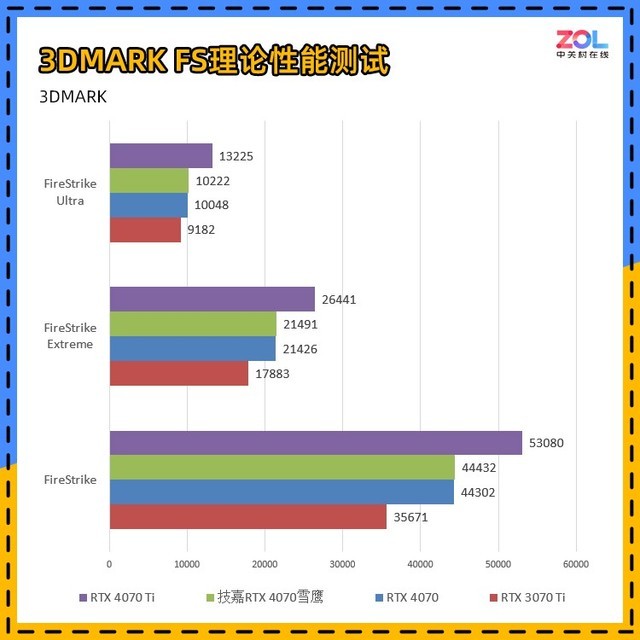
在针对显卡DX11性能的3DMARKFS套装测试中,技嘉 RTX4070雪鹰主要对比上一代RTX 3070 Ti,其中FS提升了25%;FSE提升了20%;FSU提升了11%,综合来看相比RTX 3070 Ti的性能提升约为18%。
而对比刚刚发布的RTX4070Ti,综合成绩相差20%左右。
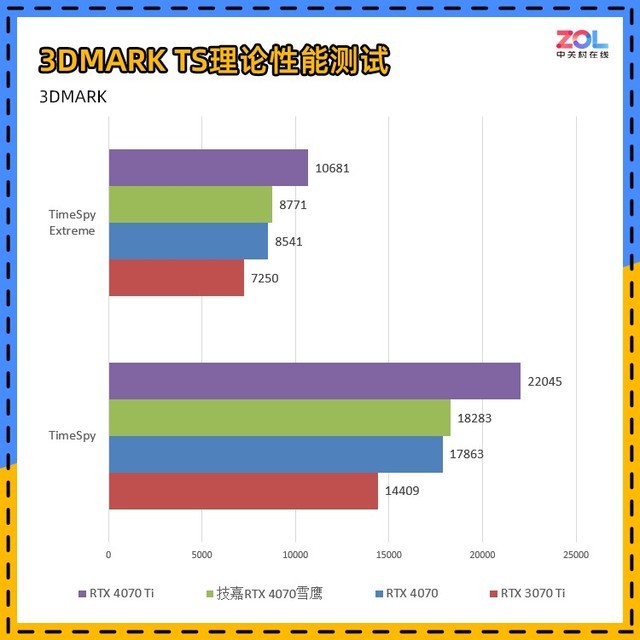
而在针对DX12环境下的Time Spy和Time Spy Extreme测试中,技嘉 RTX4070雪鹰相较RTX 3070 Ti的提升分别为:TS提升27%;TSE提升21%,综合下来约为24%。
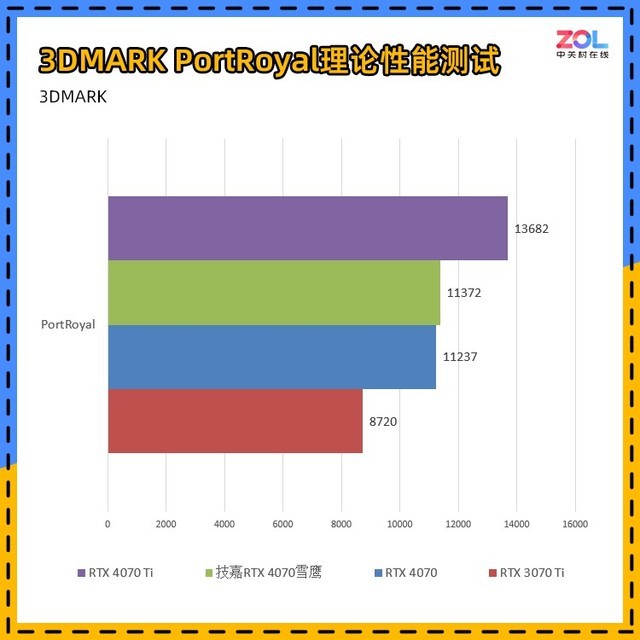
PortRoyal是3DMARK中专门针对光追性能的测试项,技嘉 RTX4070雪鹰相较RTX 3070 Ti的提升约为30%。
综合来看,技嘉 RTX4070雪鹰的理论性能相较RTX 3070 Ti的提升约为24%。
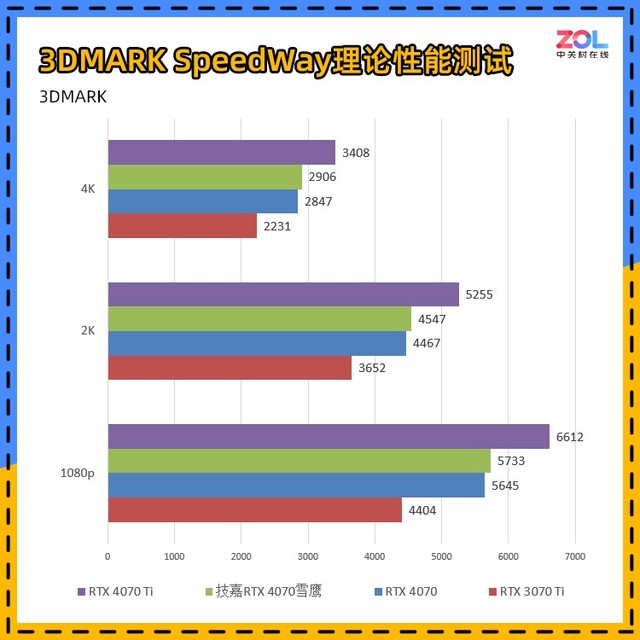
Speed Way测试是3DMARK最新更新的用于测试DirectX12 Ultimate 性能的显卡基准测试。要运行此测试,显卡必须支持 DirectX 12 Ultimate 并包含 6GB 及以上显存。
这项测试结合了实时光线追踪和传统渲染技术来测量显卡性能。场景含有光线追踪反射、实时全局光照、网格着色器、体积照明、粒子和后处理效果。并且有意思的是,Speed Way测试支持自由探索场景,可查看光照及摄像机设置的改变如何影响视觉效果。
对比RTX 3070 Ti显卡,从1080p分辨率到4K提升依次为:30%/25%/30%。
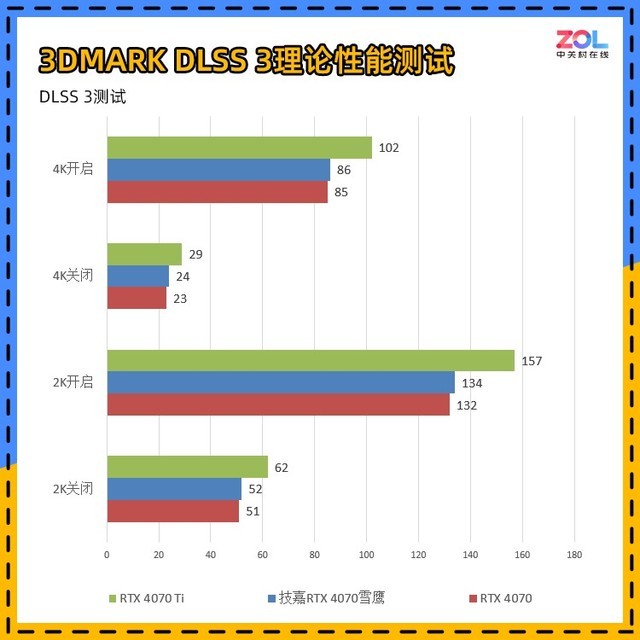
另外我们使用3DMARK刚刚更新的DLSS 3进行了相关性能测试。并且由于RTX 3070 Ti无法开启,故不参与测试,仅对比RTX4070Ti。
5 常规游戏 性能测试
由于本次RTX 40系加入了DLSS 3新技术,所以后面会进行单独测试,这里依然选择主流的几款3A大作进行游戏性能对比。
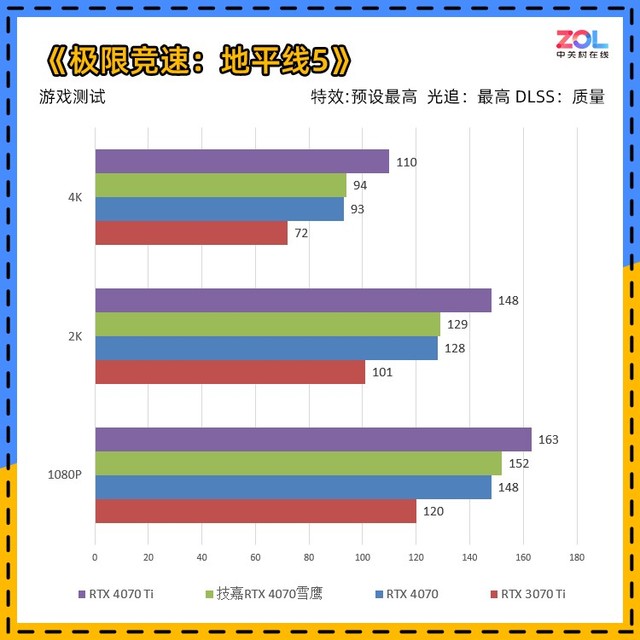
在《极限竞速:地平线5》中,加入了DLSS 3,我们在后面会进行相关测试,这里仅看常规对比。
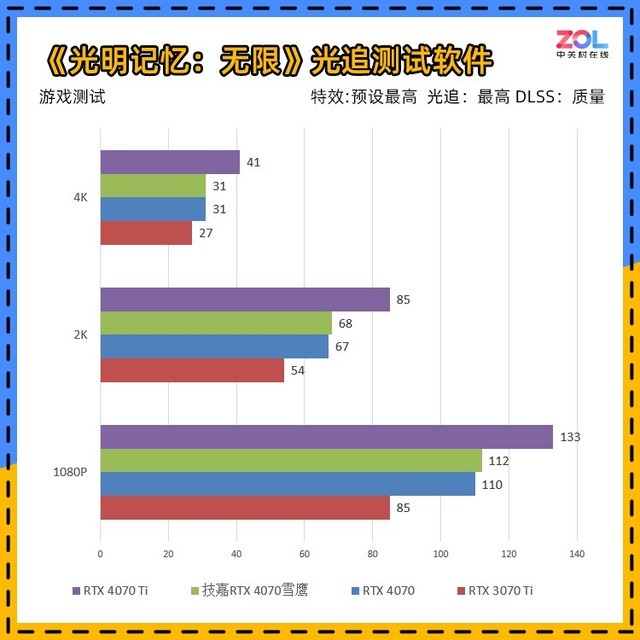
《光明记忆:无限》的光追测试软件是独立于游戏的测试工具,比游戏中用到的光线追踪技术更多,测试条件为“RTX最高/DLSS质量”。所以测试帧数相对较低,但实际游戏配置相当亲民。
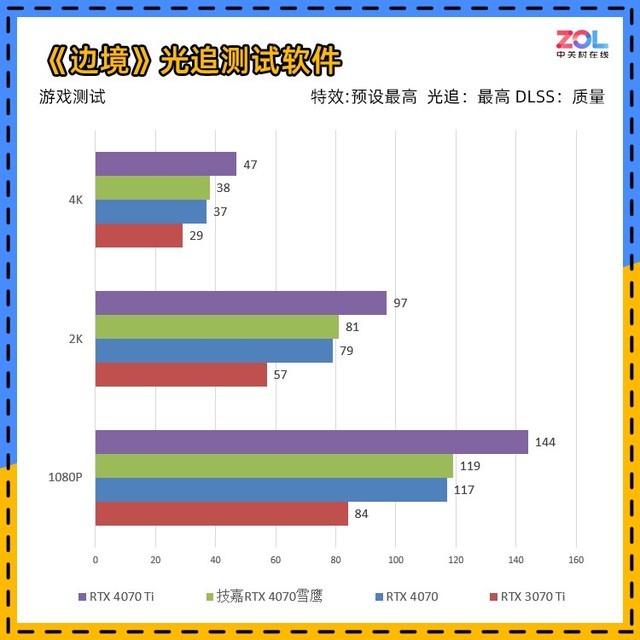
在另外一款国产游戏《边境》的跑分软件中,情况基本与《光明记忆:无限》相同,测试条件均在“RTX最高/DLSS质量”下进行。
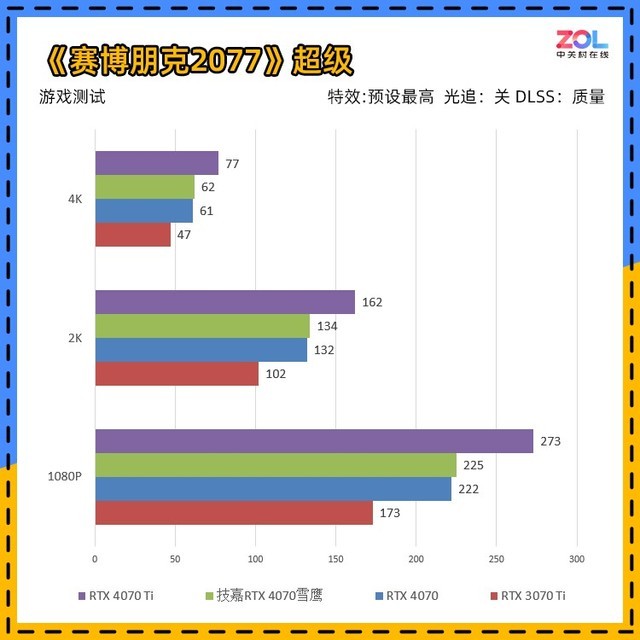
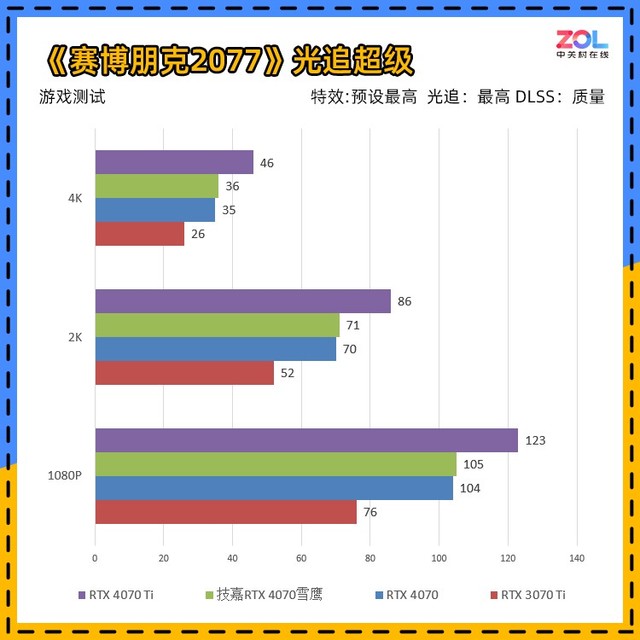
在《赛博朋克2077》中,游戏分为超级和光追超级两种最高画质。
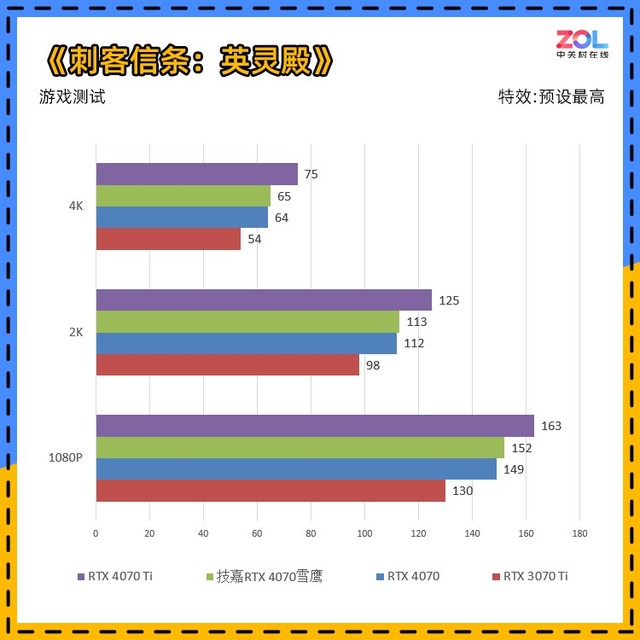
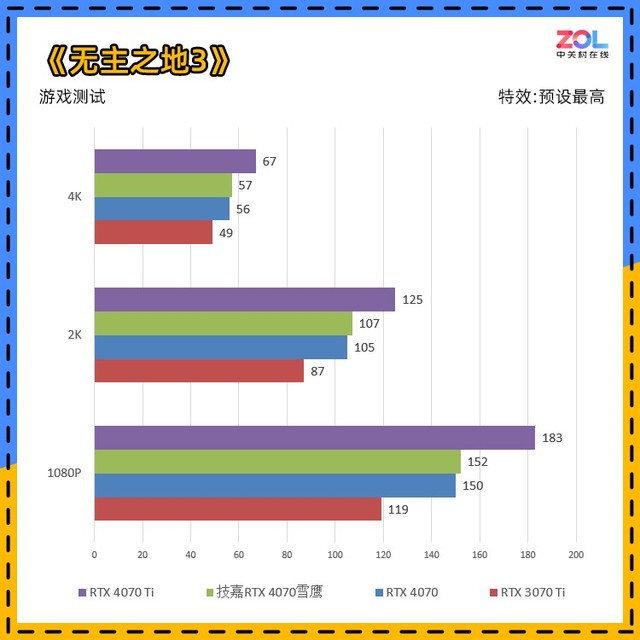
在传统的3A游戏中RTX 4070整体提升并没有光追游戏来的多,所以看来NVIDIA这些年潜心研究的光追和DLSS还是非常有用的。
6 DLSS 3性能测试
截止目前,已有超过290款游戏和应用支持DLSS,其中超过30款游戏已经支持最新的DLSS 3。
包括《逆水寒》、《微软模拟飞行》、《毁灭全人类2:重新探测》、《瘟疫传说:安魂曲》、《光明记忆:无限》、《暗影火炬城》、《F1 22》、《生死轮回》、《漫威蜘蛛侠:重制版》、《超级人类》、《极限竞速:地平线5》、《赛博朋克2077》、《红霞岛》、《暗黑破坏神4》、《侏罗纪世界:进化2》等等。
下面就让我们来实际测试,拥有全新的DLSS 3的游戏,能达到何种帧率。

本次DLSS 3的测试图表比较繁琐,并且增加了1% Low FPS和延迟的测试。
首先,游戏benchmark通常测试的FPS即为,一段时间内的游戏平均帧。而1% Low FPS则是将一段时间内的帧数从大到小排列,取最小的1%出来,再对这1%的数求平均值。
其实简单来说,这两个数值都不能代表我们在游玩时,具体哪一刻的感受,但FPS更注重整体,而1% Low FPS则是从最差的里面求平均,更谨慎一些。

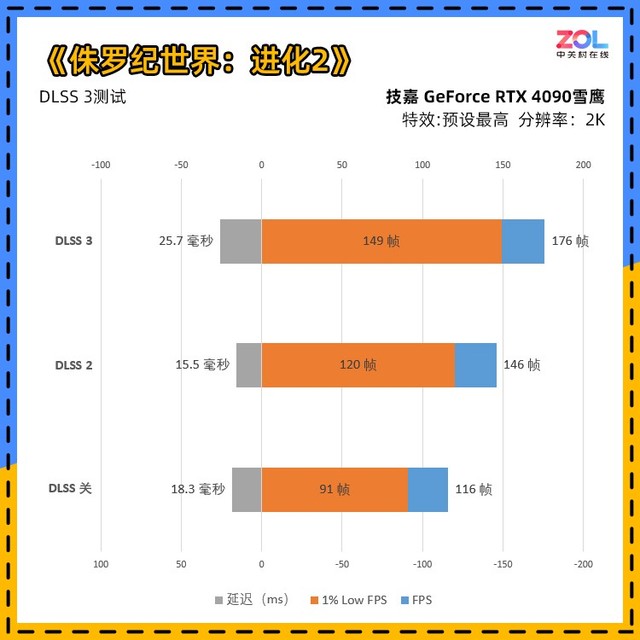
看懂了1% Low FPS,我们再来看这张图表,在坐标轴左侧的为延迟(越低越好),坐标轴右侧的均为帧数(越高越好),并且由于牵扯到正负坐标,所以两侧的值有可能会不同。
在《侏罗纪世界:进化2》中,DLSS 3的表现非常亮眼,由于此类模拟经营游戏的特点就是同屏单位多,更加占用CPU资源,而DLSS 3能够进行帧生成,来突破CPU瓶颈限制。
不过帧生成并不是毫无弊端,这也是为什么此次测试加入了延迟。并且在开启DLSS 3后,NVIDIA Reflex是捆绑开启的。但相对于绝大部分的非竞技游戏来说,25毫秒的延迟在实际体验中的感受并不强。

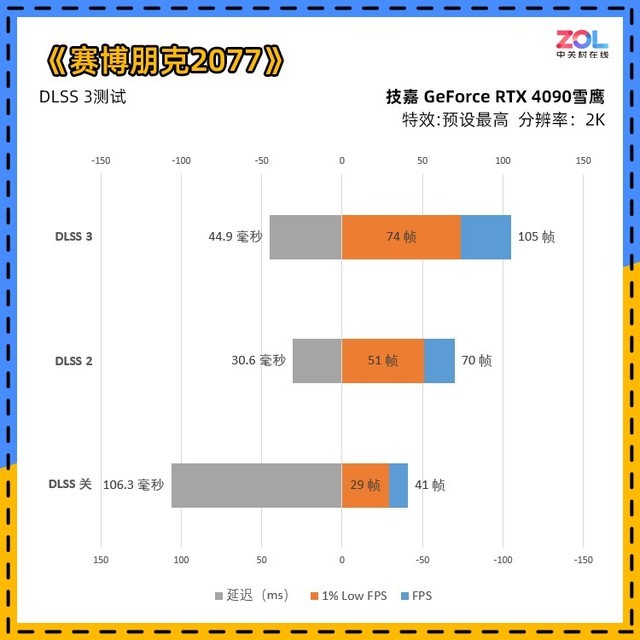
在《赛博朋克2077》中的数据反映比较真实,可以看到在DLSS关的光线追踪最高的情况下,即便技嘉 RTX4070雪鹰显卡也只有41帧,并且延迟达到了106.3毫秒。
而在开启DLSS 3后,帧数为105,提升了156%。虽然相比DLSS 2的延迟高了14毫秒左右,但依然维持在较低的水平。

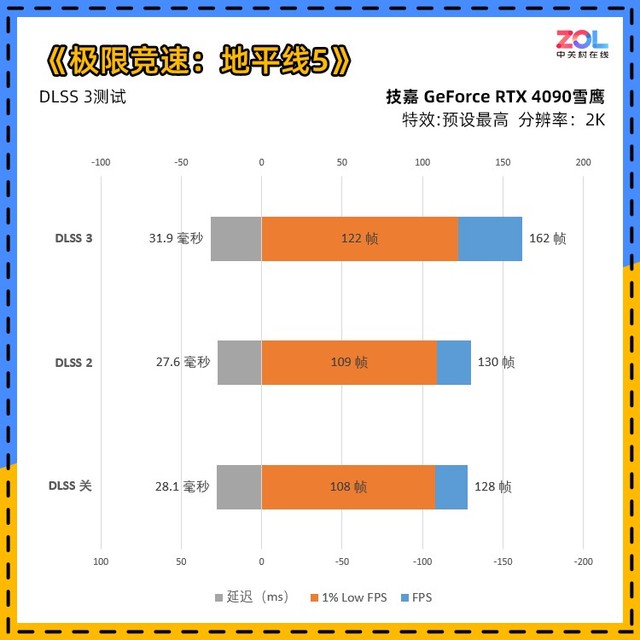
《极限竞速:地平线5》是最新加入DLSS 3的游戏,可以看到,即便在开启DLSS 2的情况下,帧数受到CPU瓶颈限制,几乎与DLSS关闭帧数相同。而在开启DLSS 3后,一下跃至162帧,提升27%。

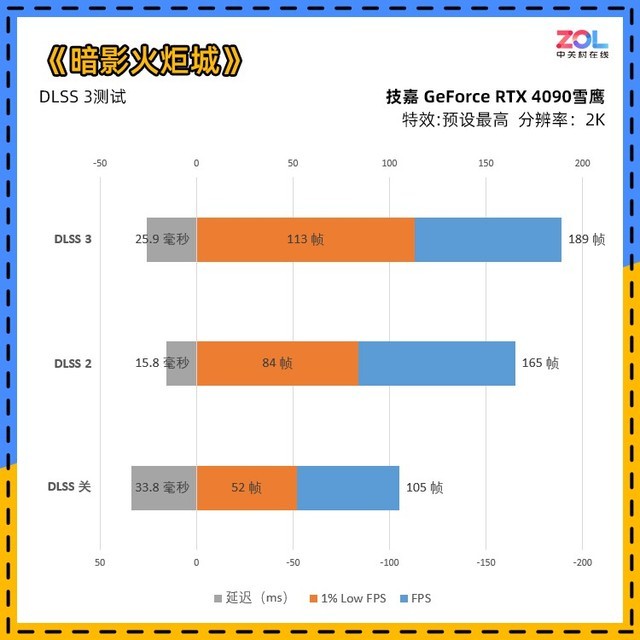
《暗影火炬城》在开启光追后对于性能要求明显提高。其中DLSS 3相比DLSS关的帧数提升了80%,DLSS 2的提升则达到了57%。
不过此次《暗影火炬城》,相比刚刚发布时,1% Low帧数有明显下降,在实际游玩中也能明显感受到异于常理的突然卡顿……大概是游戏随着版本更新,优化还没有跟上。

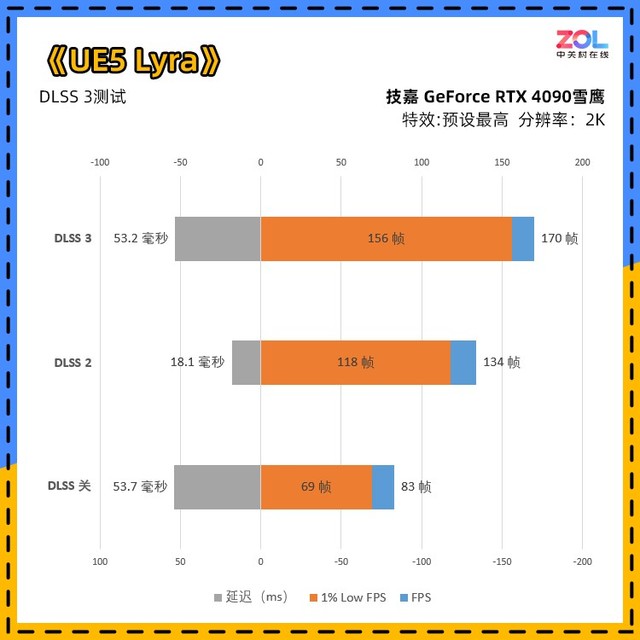
在UE5提供的测试游戏中,方便的给出了DLSS的快捷测试,这里分为DLSS关(超分辨率关+帧生成关+Reflex关);DLSS 2(超分辨率性能+帧生成关+Reflex开);DLSS 3(超分辨率性能+帧生成开+Reflex开)三档测试。
另外,由于Lyra帧数均为静态所得,1% Low的分数相比其他游戏更高一些。
7 Stable Diffusion AI绘画测试
除了游戏之外,AI也是目前大火的领域,尤其以Stable Diffusion为最,现在很多AI生成的图片完全能够以假乱真,下面我们也来测试一下RTX 4070在这方面的表现。
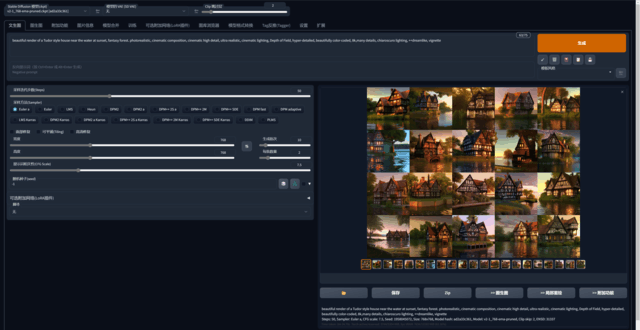
Stable Diffusion可以说几乎没有门槛,但本地部署的繁琐程度劝退了很多用户。上图为操作界面用户可根据自己想要生成的图片细节丰富关键词。

按照NVIDIA提供的关键词,我们生成了10批,共20张图片,上面挑选了两幅细节比较合理的进行了展示。

RTX 4070运算时间 2m24.79s 约合 7.2秒一张图

RTX 3070 Ti运算时间2m54.34s 约合 8.7秒一张图
Stable Diffusion对于显卡的要求比较高,这就需要显卡拥有较强的Tensor算力。
另外它对于显存的要求非常高,如果有条件的话尽量选择大容量显存的显卡。
我们对比了RTX 4070和RTX 3070 Ti在相同设置下的运算时间,两款显卡在生成20张图片的时间差距为30秒,差距还是比较大的。

另外我们也测试了使用CPU,在相同设置下生成图片,但如图片所示,保守估计需要3小时30分左右。
并且在使用CPU渲染时经常会提示内存不足,不过我们的测试平台为最旗舰的i9-13900K,内存为D5 7200MHz 32G(16G*2),可见一款趁手的显卡对于追赶潮流也是很重要的。
PS:目前AMD显卡无法使用Stable Diffusion生成图片,只能期待后续优化。
8 AV1编码测试
本次AV1编码测试选择了剪映专业版,作为有一定剪辑基础的人来说可能不屑一顾,但整体测试下来的感觉还是非常好用的。
我日常剪辑会使用到PR、AE等Adobe全家桶软件,剪映最大的感受就是更智能化,且预设更符合大众使用,更有智能识别字幕等便捷工具。
如果要比喻的话,剪映和PR就好像美图和PS,Adobe的优势就是可操作空间更大。但我们日常使用的话,剪映这类软件完全没有问题,更易上手。
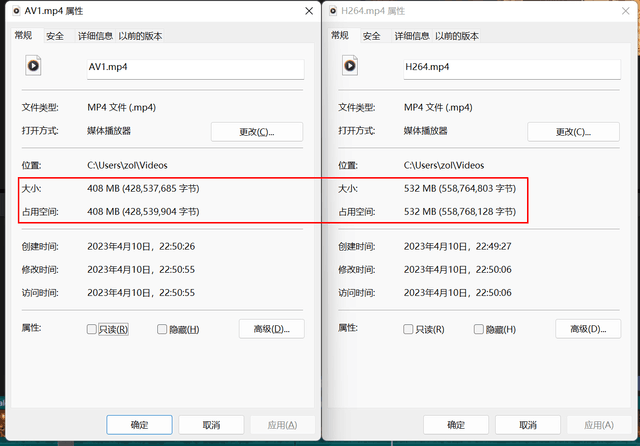
剪映专业版目前自带AV1编码输出,在实际测试中,我们导出一段2分钟左右的视频。可以看到两个文件容量相差124MB。
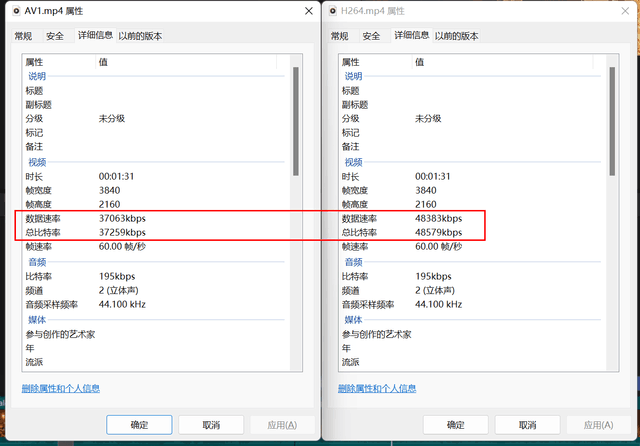
由于AV1编码特性,生成文件的比特率更低,但视频清晰度则完全相同。所以如果生成同比特率,同容量的文件,AV1将会更清晰。
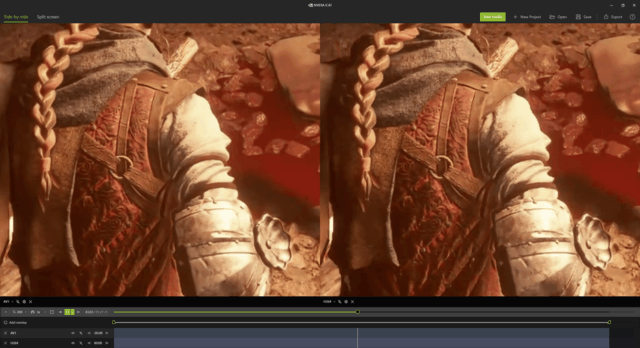
我们通过NVIDIA ICAT来进行两段视频的画面对比,图中左侧为AV1编码,右侧为H264编码。反正通过200%的细节放大,几乎看不出任何区别。
9 RTX VSR(RTX Video Super Resolution)测试
目前RTX VSR(RTX Video Super Resolution)已经在部分浏览器中进行测试,首先玩家需要更新到NVIDIA最新驱动,在NVIDIA控制面板中的【调整视频图像设置】可以看到最新的RTX 视频增强超分辨率。
RTX VSR是 AI 图像处理的突破,它超越了传统的边缘检测和特征锐化技术,极大地提升直播视频内容的质量。
开启RTX VSR不仅需要最新版驱动,还需要使用RTX 40或30系列GPU,并且几乎适用于Google Chrome和Microsoft Edge浏览器中的所有视频内容(浏览器也需要更新到最新版本)。
开启后,目前已知的打开YouTube或者B站,都可以享受到RTX VSR效果的加成。
如果不确定,在全屏播放视频时,可以打开任务管理器,看到GPU负载增加,即为开启成功。
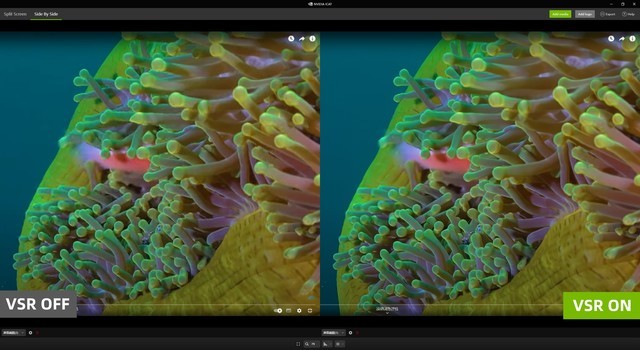
(点击放大查看原图)
我们打开YouTube随意观看视频,在打开RTX VSR后,可以清晰明显的看到水下珊瑚的质量明显提高,边缘更为清晰,并且极大减少了失真现象。
10 温度及功耗测试
功耗测试中,我们选择FurMark软件进行拷机测试,并采用GPU-Z检测温度,功耗仅计算显卡自身。
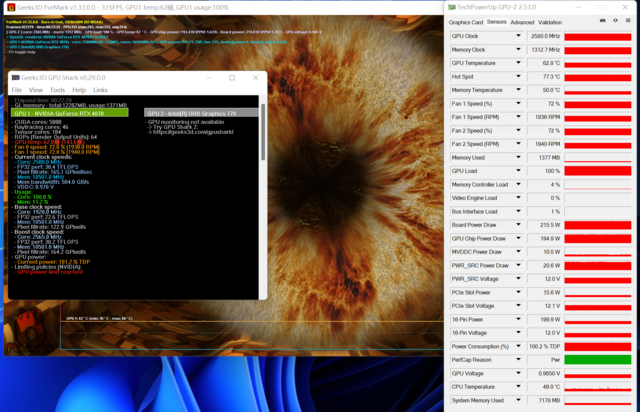
可以看到技嘉 RTX4070雪鹰这张显卡对于温度的控制非常不错,我们评测室温控制在26℃左右,通过20分钟左右的拷机测试,TDP达到100%,板载功耗为215W;温度一直控制在63℃左右,热点温度在77℃左右。
令人在意的是,通常显卡的显存温度也会比较高,而技嘉 RTX4070雪鹰的显存温度仅有50℃。
游戏动态功耗测试
值得一提的是,本次我们在拷机测试中最大板载功耗为215W左右,TDP达到了100%。但在实际游戏测试中,大部分3A游戏能够在180-190W左右,一些非常耗费性能的3A游戏才能够到达200W左右,远低于额定功耗。
所以在实际的使用过程中,由于不同游戏负载不同,GPU的实际功耗是动态变化的,类似于FPS随时间的变化,RTX 40系列很难触及功耗墙。
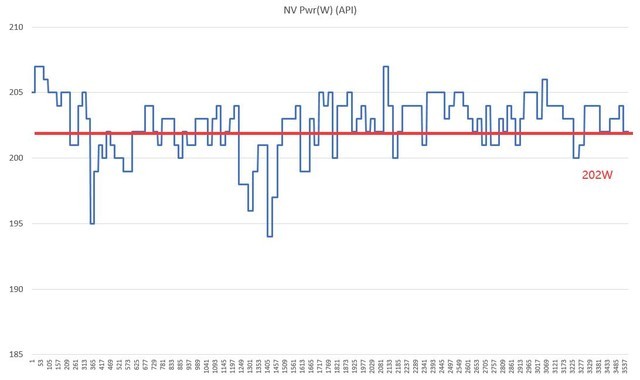
技嘉 RTX4070雪鹰 3A游戏平均功耗为200W
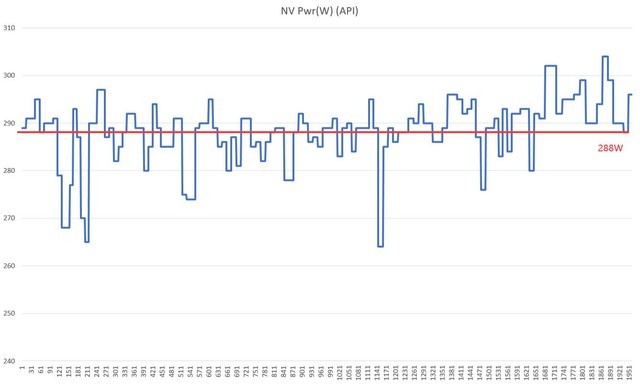
RTX 3070 Ti 3A游戏平均功耗为288W
在实际的游戏功耗测试中,我们选择《赛博朋克2077》自带benchmark,画面设置为光追超级、4K分辨率,来强行拉满两张显卡的性能极限,检测我们实际应用场景的功耗。
可以看到两款显卡虽然均为70级别,但刚刚发布的RTX 4070平均功耗为202W,而RTX 3070 Ti则是288W,低了80W左右,这的确是一个惊人的成绩。
11 不一样的白色金属质感
白色产品近几年一直是厂商和用户比较偏爱的,而白色显卡为了在质感上做到更“纯粹”,大部分都选择了更统一的材质。而技嘉 RTX4070雪鹰整卡都选择了两种材质拼接,尤其是正面导流罩覆盖了大面积的金属材质面板。两种看似不太搭调的材质,组合在一起却意外地和谐。
而且雪鹰这张卡没有过分强调RGB灯光效果,虽然白色作为中性色非常百搭,但过分强调灯光效果,会让原本契合度刚好的两种材质打破平衡。
本次RTX 4070的发布,将RTX 40系显卡售价首次拉至5000元以内,对于憋了几年想要攒机的单机游戏玩家来说,绝对是利好消息。
性能上,RTX 4070可以在3A游戏中,2K分辨率下达到百帧的成绩,而且我们所测试的游戏画面均为中上等。至于4K,目前大部分独立游戏或者网游也都没有问题。
在整体RTX 40系显卡中,最有意义的升级,我认为在于功耗的下降。并且目前大部分AIC显卡都采用了单8pin供电。同级别产品功耗下降100W,综合性能提升20%左右,这才是GPU升级的意义所在。

另外RTX 40系显卡在设计之初也更注重多领域用途,不止局限于游戏。所以即便RTX 4070定位游戏人群,在生产力工具上,它依然有一席之地。
价格上这款AERO雪鹰由于是超频版,目前上到了5299元,技嘉一些标频显卡如风魔,同样在4799元左右。

技嘉(GIGABYTE)RTX4070 12G显卡 魔鹰/雪鹰/超级雕/风魔 网吧台式机电脑游戏独显 4070 AERO OC-12GD 雪鹰
[经销商] 京东商城
[产品售价]
12 附录1-NVIDIA Ada Lovelace架构解析
Shader Execution Reordering (SER)着色器执行重排序
SER主要的作用是提升着色器性能,它可以将效率低下的工作负载,动态重组为更高效的工作负载。主要针对光线追踪的性能提升非常大。
简单地说,GPU在执行类似工作的时候效率最高。但随着光追效果越来越强大,每个场景可能有数百万条光线照射在不同材质上,而我们知道不同材质的反射率,以及反射效果也是不同的。所以这样就为着色器创建了大量的、发散的,效率低下的工作负载。
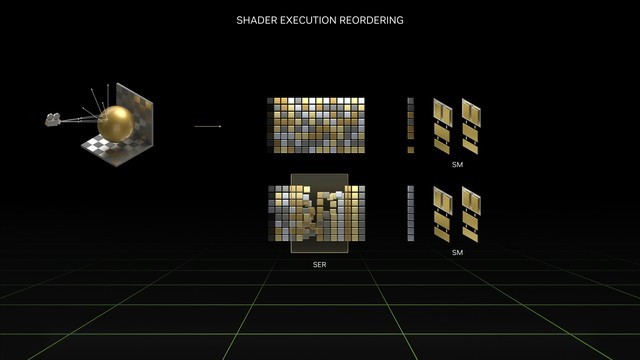
SER则可以将这些杂乱的指令重新分门别类,动态重组为更高效的工作负载。根据NVIDIA的说法,SER可将着色器性能最多提升2倍,并将游戏帧率最高提升25%。
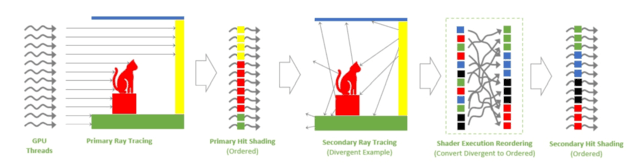
举个简单的例子,当光线第一次从发射端到碰撞端是非常有规律的射线,而碰撞到物体后的二次光追,则会出现大量发散的、无规律的反射,这对于光追负载是非常高的。而从图中便能看到,SER可以将这些指令进行二次排序,以发挥出着色器的最大性能。
不过好在这么实用的功能并不是RTX 40系的专利,它是一个易于集成的SDK,目前需要游戏开发商集成在游戏中。另外由于它是一个通用的逻辑,后续也有可能直接集成在Windows的API中,这样游戏开发者就无需特意引用,直接调用系统API即可。

可以说SER对于手持RTX 20系及以上(能够开启光线追踪)的N卡用户来说,是极大地福音。毕竟免费提升的光追性能,谁不喜欢呢。
第三代 RT Cores
RT Core的作用在于更快的光线追踪计算能力,如果说在RTX 30系显卡中,想要畅享4K高帧率游戏有点吃力,那么RTX 40系显卡中,将显得轻而易举。
在GeForce RTX 4090这张显卡上,达到了191 RT-TFLOPs的处理能力,而RTX 30系显卡最快处理能力为78 RT-TFLOPs,足足为2.4倍。并且根据NVIDIA的官方说法,第三代RT Core的峰值RT-TFLOPs相比于前代提高了2.8倍。而这只能说明,这张4090并非Ada Lovelace架构的最终形态。
Opacity Micro-Map Engines
在第三代RT Cores中引入了两个重要的硬件单元,首先是Opacity Micro-Map Engines,可以理解为微映射透明度引擎,它主要的作用是优化光线追踪渲染,可大幅减轻着色器的工作负担。
比如树叶之类的复杂物体,不同的光线都会影响它的表现状态,以及树叶之间的光线反弹,所以对于光线追踪的计算量是巨大的。

不过Opacity Micro-Map Engines可以将光线追踪特性烘焙到不透明蒙版中,所以那些不规则形状和半透明的对象,也就能够更快更精准的渲染出来,从而极大减轻着色器的工作负担。
Displaced Micro-Mesh Engines(DMM)
Displaced Micro-Mesh Engines可理解为微网格置换引擎,它构建光线追踪的BVH(Bounding volume hierarchy)的速度提高了10倍!所使用的的显存减少了20倍!

DMM由第三代RT core本地处理,与前几代相比,它只使用基本三角形渲染复杂几何图形,极大减少了存储和处理需求。
具体的工作原理从图中一目了然,新的DMM可以将面数非常多的复杂图形做简化,创造出简单的模型,但整体的光线追踪效果不变。

通过一些模型数据我们可以具体看到,新的DMM将模型简化了多少。原本1100万三角面的模型,经过简化后,只有15万左右的微网格,BVH的构建速度提升了8.5倍,小了6.5倍。
而这还不是最夸张的,越复杂的模型往往优化的效果越好,在官方展示的这几组对比示例中,最快可提升大于15倍的速度,容量简化20倍的模型。
第四代 Tensor Cores
除了光追单元的升级外,第四代张量核心的升级更加恐怖。它采用了新的FP8张量引擎,在旗舰型号RTX 4090显卡上,吞吐量达到了1.32 Tensor petaFLOPs,提高了5倍。
注意这里的单位――petaFLOPs。以往的TFLOPs为万亿次浮点运算,而petaFLOPs则为千万亿次浮点运算。
而在中端的RTX 4070上也达到了惊人的466 Tensor-TFLOPS,相比上一代RTX 3070 Ti,拥有2.7倍左右的提升。
DLSS 3
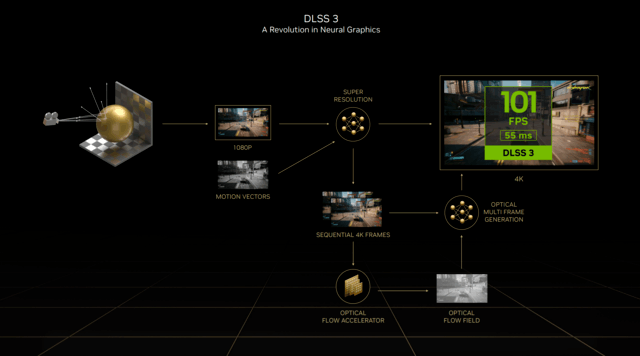
本次推出的DLSS 3也是RTX 40系一大卖点,从DLSS 2.3直接迈入了DLSS 3版本,也能看出此次的升级之大。而DLSS 3也被NVIDIA官方称为神经网络渲染新时代。
全新的DLSS 3在原有的DLSS超分辨率的基础上,添加了光学多帧生成技术,以生成全新的帧,而不像原来只能生成像素。
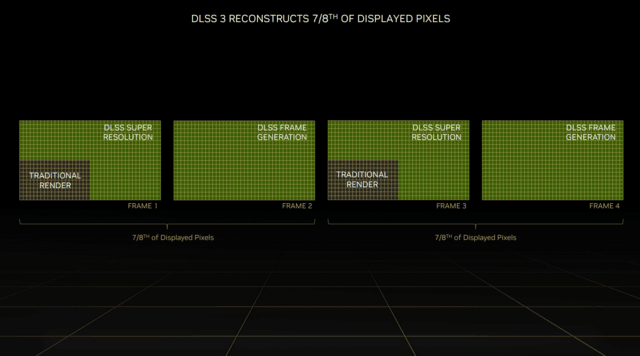
DLSS 3结合了DLSS超分辨率、DLSS帧生成和NVIDIA Reflex这三大技术,能够重建八分之七的像素,极大提高性能。
在GPU受限的游戏中,比如2K分辨率及以上的更高分辨率,DLSS 2能够将帧率提高2倍,DLSS 3则能够提升4倍。
本次DLSS 3跨越了一个大版本,从想法和原理上也再度升级,完全“猜想”1帧的技术,我们解释起来简单,但实施起来需要大量的推理与演算,以及绝对超前的想法。
不过“凭空”生成的1帧,在延迟上绝对要比DLSS 2高。所以此次完整的DLSS 3中,捆绑了NVIDIA Reflex,可以有效帮助减小延迟。

这也不负NVIDIA给它起了个“神经网络渲染新时代”的名号。纵观目前市面上的XeSS、FSR技术,DLSS绝对称得上“巨人的肩膀”。当然,连年的创新,苦的是手持上一代显卡的玩家,想体验DLSS 3的帧生成,目前唯一的办法就是购入一张RTX 40系显卡。
New Optical Flow Accelerator
New Optical Flow Accelerator光流加速器是在第四代Tensor Cores中最新引入的,这也是为何DLSS 3中的帧生成为RTX 40系显卡独享。
光流加速器在原本DLSS 2的基础上,还可以计算两个连续帧内的光流场,能够捕捉游戏画面从第1帧到第2帧的方向和速度,从中捕捉粒子、反射和光照等像素信息。并分别计算运动矢量和光流来获得精准的阴影重建效果。

以《赛博朋克2077》为例,在第一帧,光流加速器会捕捉到每一个像素中的粒子、反射和光照等信息。并在第二帧中查找匹配的像素区域,计算帧之间的差值。
如果说原来DLSS 2能够“猜”出一张图剩下的像素,那么DLSS 3除了这些,还能够“猜”出下一帧的画面。

另外由于DLSS 3的帧生成是在GPU中处理和运行的,所以即使遇到CPU瓶颈的游戏,AI同样能够提升帧率。这也是为什么在此次发布会中说到,DLSS 3能够突破CPU的限制来提升帧数。
AV1编码器
本次升级的第八代NVENC编码器可以说是直播、视频、后期工作者的极大福音。它首次加入了对AV1编码的支持,最显而易见的效果就是直播。
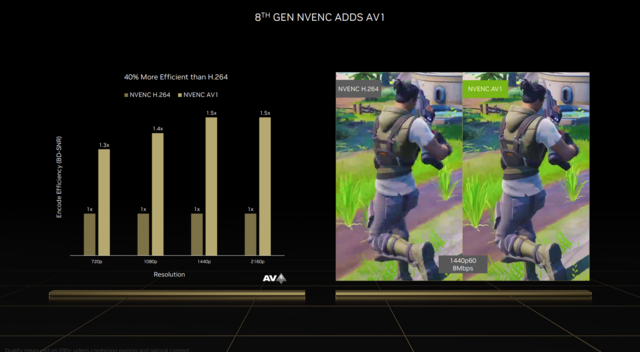
相比传统的H.264编码,AV1编码的效率平均提升了40%,在同码率下AV1编码的画质将更好。目前大部分直播的分辨率和清晰度,均受限于平台规定的最大比特率。以Twitch限制的8Mbps为例,可以看到在同等带宽下,同为2K 60帧的画面,采用AV1编码的清晰度明显比H.264更高。
说起直播,OBS相信大家都不陌生,在10月份即将发布的补丁中,OBS就加入了对NVENC的AV1编码支持
当然,直播只是我们更容易见到的AV1优势,在视频工作的所有环节,AV1编码都可以带来极大提升。
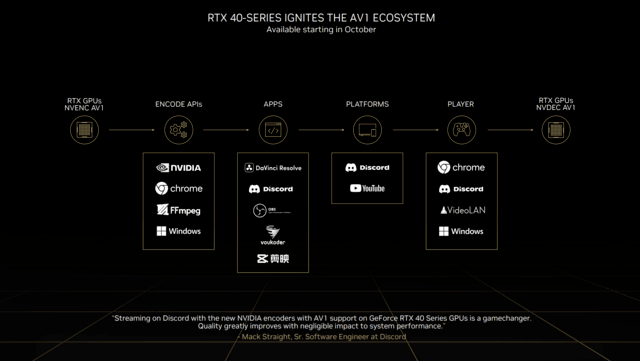
所以,如图所见。NVIDIA已经为广大用户铺好了一条完整的生态链,从编码API、软件、平台到播放器,将全面支持AV1编码。
另外再说一下NVIDIA一直强调的在RTX4070Ti及以上型号配置的双AV1编码。顾名思义,即部分显卡内搭载了两个编码器,它所带来的效果也是显而易见的。
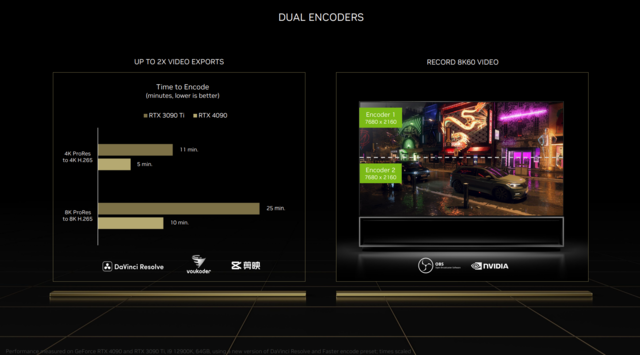
首先,根据官方宣传的,在4K H.265的导出速度上,RTX 4090是RTX 3090 Ti的2.2倍;在8K H.265的导出速度上更是达到了2.5倍。这部分的提升,大家常用的剪映同样适用,感兴趣的用户不妨亲自体验一下。
除了导出速度,8K 60帧的视频录制在以前简直难以想象,而双编码器的好处就是可以将图像一分为二,两个编码器分别处理7680×2160的图像信息,最后拼合完整。
关于编码部分,可能大部分用户的感受不深,但当有一天,你想录屏的时候,却发现显卡不支持,才会发觉它的重要性……
随着图像逐渐进入到超清时代,硬件编码和渲染几乎已经成为不可或缺的帮手。虽然论质量,硬件编码仍不及CPU软编,但软编做到了极限画质,也要承受时间的无穷长。甚至在一张8K渲染图中,两种编码方式的时间差距就已经达到了几个小时,遑论一段10秒的CG动画。在不断进步的硬件编码中,质量和时间也在不断地被挑战和刷新。
13 附录2-Ada Lovelace是谁?
Ada Lovelace(1815-1852)是英国数学家、计算机程序创始人,建立了循环和子程序概念,被称为世界上第一位程序员。
Ada从小对数学有极高天赋,其父称她为“平行四边形公主”,后来的合作伙伴Charles Babbage称她为“数字女巫”。在19岁时Ada嫁给了自己曾经的科学家庭教师,婚后的她对数学热情不减。

1842年到1843年花了9个月时间翻译了Babbage的《分析机概论》的备忘录,写了很多注记,其中给出了用计算机进行Bernoulli数求解的详细说明。由此,Ada被广泛认为是世界上第一个程序员。
而以她名字命名的语言――ada语言,已经成为了美国军方开发战斗机等尖端武器的语言。
从几行简短的生平简介中,不难看出Ada的生命虽然只经历了短暂的37个春秋,但却足以被后人铭记。
这也是为什么此次NVIDIA RTX 40的先行宣传中,用到了“以未来敬传奇”的slogan。





