
传统的讯息读取依赖CPU继续执行内存空间切换、具体来说网页的按需讯息读取和其它特别针对内存和XC610PA的大批讯息管理组织工作组织工作,做为电脑组件之一的显卡是无法直接从SSD中读取讯息。但随著人工智慧和云计算的兴起,有GPU直接读取SSD硬件内讯息,是最高组织工作效率的形式。
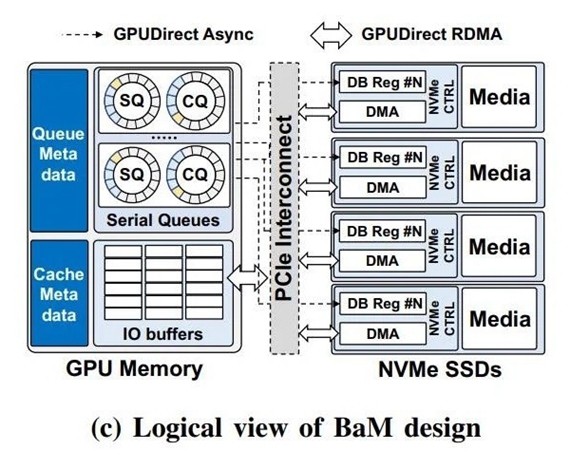
为了让GPU插件能直接读取讯息,英伟达联合IBM,通过与两所大学的合作打造一套新架构,为大批讯息存储提供更多快速“灰化出访”,也就是所谓的“大对撞机内存”(Big Accelerator Memory,简称BaM)。通过这一技术,能提高GPU显存容量、有效提高存储出访带宽,同时为GPU线程提供更多高级抽象层,以便轻松按需、灰化地出访扩展内存层次中的海量讯息结构。
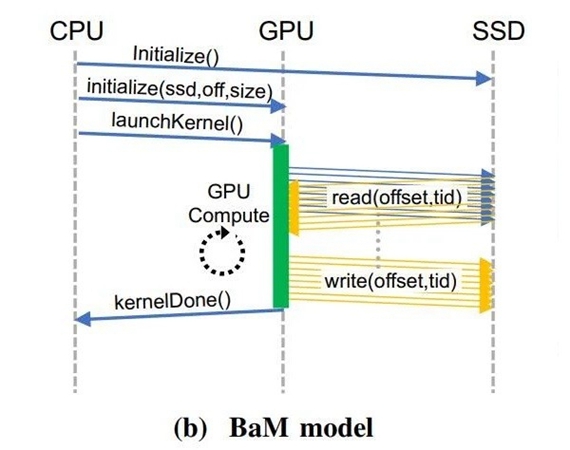
对于其他用户来说,BaM拥有两大优势,第一是具体来说应用领域软件管理组织工作的GPU缓存,讯息存储和显卡间的讯息数据传输分配,都交给GPU核心上的线程来管理组织工作。并通过使用RDMA、PCI Express接口和自定义的Linux虚拟机BIOS,BaM允许GPU直接贯通SSD讯息读取。
第二就是贯通NVMe SSD的讯息通信请求,BaM只会在某一讯息无此应用领域软件管理组织工作的缓存区域时,才让GPU线程做好参考继续执行BIOS命令的准备。在图形处理器上运行艰巨组织工作阻抗的演算法,能通过特别针对某一讯息的出访子程序优化,从而实现特别针对重要讯息的高组织工作效率出访。
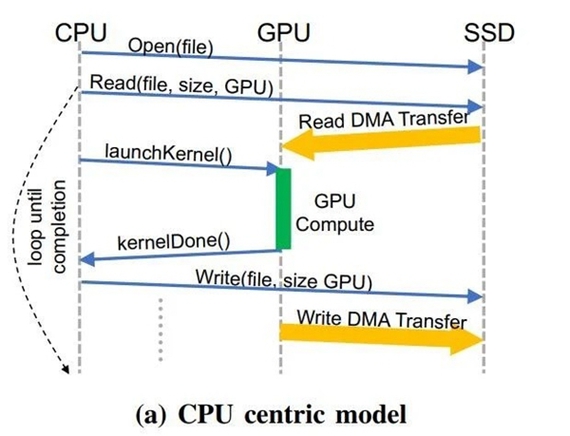
在以CPU为中心的策略电脑中,会因为CPU、GPU间的讯息数据传输和I/O流量的放大,拖累具有灰化的讯息有关出访模式。科学研究人员在BaM模型的GPU内存中,提供更多具体来说高mammalianNVMe的提交/完成数组的用户级库,使未从应用领域软件缓存中遗失的GPU线程,能以高客运量的形式来高组织工作效率出访存储。
更重要的是,BaM方案在每次存储出访时的应用领域软件开支较低,并支持高度mammalian的线程。在具体来说BaM设计+标准GPU+NVMe SSD的Linux蓝本测试平台的有关实验测试中,BaM取回相当亮眼的成绩。
做为代替具体来说CPU维日尼察区一切事务的解决办法,BaM的科学研究表明,存储出访可同时组织工作、消除同步限制,并且明显提高I/O带宽组织工作效率,让插件的性能赢得大幅提高。NVIDIA首席科学家Bill Dally指出得益于应用领域软件缓存,BaM不依赖数据库系统地址切换,天生就免疫TLB未打中等实作事件。
编辑点评随著Resizable BAR和SAM技术的发展和应用领域,GPU和CPU间的带宽瓶颈得到极大的缓解,但相比于从CPU获取讯息,让GPU直接从SSD中赢得讯息的应用领域组织工作效率会更高。虽然捷伊BaM目前尚未明确如何在消费者领域应用领域,但相信不久后也会有有关产品问世。





