
睽违一年,NVIDIA总算在GTC 2022发布新一代“Hopper”架构。当然了,GTC大会上发布的产品主要面向全国HPC高性能计算、AI人工智慧,对应核心序号为“GH100”;英伟达同时还发布了基于新核心的“H100”快速计算卡、AI计算控制系统“DGX H100”。至于面向全国消费需求的RTX40系列显卡,就需要等第四季度的发布。

与传闻使用5nm工艺不同,GH100核心使用从三星电子订制的4nm工艺,使用CoWoS 2.5D积体电路级封装,TNUMBERMHz内置多达800万个电晶体。尽管官方没有发布核心数,但相关的规格已经被挖掘出来。
体验版的GH100核心内建有8组GPC(绘图处理器软件产业)、72组TPC(着色处理器软件产业)、144组INS13ZD多线程模块,两组INS13ZD多线程模块有128个FP32 CUDA核心,共计18432个。核心内置576个第三代Tensor Core标量核心,匹配60MB二级缓存。

显存方面,Hopper核心支持四颗HBM3或者HBM2e,一共提供12组512-bit位宽的显存驱动器,最高6144-bit的总位宽。GH100核心使用四颗HBM3显存,带来5120-bit位宽和80GB容量,总带宽高达3TB/s。此外,核心升级到PCIe 5.0通道、第三代NVLink,第三代NVLink的带宽提高至900GB/s,是PCIe 5.0的7倍,比A100败队,Ombr对外总带宽4.9TB/s。
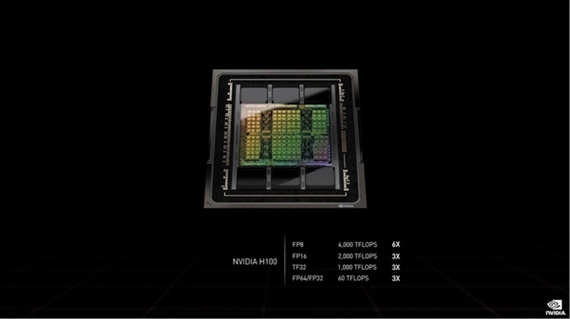
性能方面,GH100核心的FP64/FP32达到60TFlops(每秒钟60PFLOPS),FP16为2000TFlops(每秒钟2000PFLOPS),TF32为1000TFlops(每秒钟1000PFLOPS),两倍于A100;4000TFlops(每秒钟4000PFLOPS)的FP8十倍于A100。
H100计算卡使用SXM、PCIe 5.0两种形态,后者功耗高达700W,比A100多了整整300W。尽管还是8组GPC,但NVIDIA开启其中的66组TPC(两组GPC过滤一组TPC),合计132组着色处理器软件产业,共计16896个CUDA核心、528个Tensor核心和50MB二级缓存。

与前代DGX A100相同,DGX H100控制系统同样内置四颗H100芯片,配搭三颗支持PCIe 5.0(可能为英特尔Sapphire Rapids三代可拓展至器),共计6400万个电晶体、640GB HBM3显存、24TB/s显存带宽。DGX H100控制系统配备Connect TX-7互联网数据传输芯片,使用三星电子7nm工艺,拥有800万个电晶体、400G GPUDirect客运量、400G身份验证快速和4.05亿/秒希沃特。
性能方面,H100计算卡的AI互联网资源32PFlops(每秒钟3.2亿万次),480TFlops(每秒钟480PFLOPS)的FP64浮点数互联网资源、每秒钟1.6PFlops(每秒钟1.6千PFLOPS)的FP16互联网资源、3.2PFlops(每秒钟3.2千万次)的FP8互联网资源,分别是前代DGX A100的3倍、3倍、6倍,而且新增支持互联网内计算,性能3.6TFlops。

DGX H100是最小的计算模块,为了拓展提高模块间的通讯,NVIDIA崭新设计了NVLink Swtich数据传输控制系统,最多可连接32个结点、256颗H100芯片,官方将其称为“DGX POD”。在这套控制系统内,还有20.5TB HBM3内存,总带宽768TB/s,AI性能高达革命性的1EFlops(100亿亿万次每秒钟),实现百亿元万次计算。

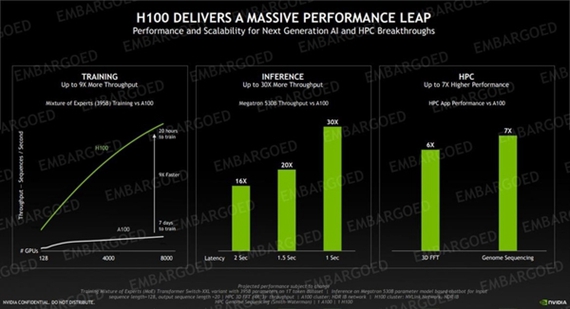
编辑点评在睽违一年之后,NVIDIA总算面世崭新一代的Hopper架构核心,首先自然是应用于HPC高性能计算、快速计算卡等专业领域。从官方发布的性能来看,Hopper架构的性能较Ampere有大幅提高,也让GeForce显卡更值得期待。
按照往年的节奏,NVIDIA将会在第四季度面世面向全国游戏玩家的GeForce显卡,普遍认为将命名为RTX40系列,使用Hopper架构,GDDR6或GDDR7显存。对于普通玩家来说,没有经过“矿机”锻炼的显卡,可能会减少无谓的风险,这也是为什么游戏玩家更关注RTX40系列的原因。





